 RAG学习笔记-理论篇
RAG学习笔记-理论篇
# RAG学习笔记-理论篇
RAG(Retrieval-Augmented Generation,检索增强生成)
检索增强生成是一种结合信息检索和生成模型的技术架构,当用户提出查询时,系统首先从外部知识库(如数据库、文档集)中检索与查询相关的最新或特定领域信息片段;然后,将这些检索到的信息作为上下文,连同原始查询一起输入到LLM中,引导模型基于提供的外部知识生成更准确、更具事实依据的回答。RAG系统首先根据查询从知识库中检索相关文档片段,然后将这些信息作为额外上下文提供给生成模型。这种方法有效解决了语言模型的知识陈旧性和信息幻觉问题。
- RAG结合了检索(Retrieval)和生成(Generation)两个模块。它通过检索外部知识库(如文档、数据库或互联网)获取相关信息,然后将检索到的内容与大语言模型(LLM)结合,生成最终的响应。
- 检索模块通常使用向量搜索、语义匹配等技术,生成模块则基于LLM(如GPT)完成内容生成。
- 传统知识库:
- 传统知识库是一个结构化的信息存储系统,通常以数据库或文档形式存在,内容经过人工整理和分类。
- 用户通过关键词搜索或规则匹配从知识库中获取信息,系统直接返回存储的内容,不涉及生成过程。
在信息处理方式上:
- RAG:
- 动态生成:RAG能够结合检索到的信息生成新的内容,而不仅仅是返回现有信息。
- 语义理解:RAG通过LLM理解用户查询的语义,即使查询与知识库内容不完全匹配,也能生成相关回答。
- 传统知识库:
- 静态返回:传统知识库只能返回预先存储的信息,无法生成新内容。
- 规则匹配:依赖关键词或规则匹配,对于复杂或模糊的查询可能无法提供准确答案。
RAG与传统知识库的主要区别在于信息处理方式和应用场景。RAG通过动态检索和生成,能够提供更灵活、实时的知识服务,适合开放域和复杂场景;而传统知识库则以静态存储和规则匹配为主,适合封闭域和标准化场景。RAG的兴起标志着知识管理与应用向更智能、更动态的方向发展,但传统知识库在特定场景中仍具有不可替代的价值。
资料 + 嵌入模型生成服务(Embedding Model) => 向量 => 存储到向量数据库(vector database) => 用户提问,从向量数据库中匹配 => 拼接新的提示词 => 发送给大模型
核心步骤
- 把资料拆分为向量格式,存储在向量数据库;
- 用户提问时去向量数据库检索相关答案;
- 把这些相关答案发送给 AI 配合一起生成最终答案。
# LLM面临的问题
- LLM 是离线训练的,一旦训练完成后,它们无法获取新的信息
- 大模型自身的知识完全源于训练数据,其训练集基本都是构建于网络公开的数据,难以覆盖垂直行业的非公开的、私域的数据
- 对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,尤其是大公司,没有人会将私域数据上传第三方平台进行训练推理。
- 幻觉:LLM 出现幻觉的本质原因是其基于概率的生成机制会优先输出"语义合理"而非"事实正确"的内容
- LLM 的不可追溯性:知识存储是『黑盒』的,用于模型训练的海量知识被压缩为千亿甚至万亿级参数,参数化知识是不可解析的;概率生成,而非事实检索;
# Prompt提示词
应用层的技术,都是为了拼出一条合适的Prompt
Prompt 是我们唯一可以和 LLM 打交道的方式,在应用技术层,无论我们做了多么炫酷的设计,最终都是为了传递适合的 Prompt 给 LLM。
Prompt分类:身份设定、背景设定、参考资料、样例、指令、限制条件等
- Zero-Shot: 提示词里没有写问答样例;
- One-Shot: 提示词里写了一个问答样例;
- Few-Shot: 提示词里写了多个问答样例;
# RAG
将参考资料、样例放在 Prompt 中,叫做 In-Context-Learning;但模型能接收的提示词有字数限制,且提示词内容多了性能会严重下降,所以需要一个知识库,需要的时候就去知识库里找一些有用的信息。
RAG,Retrieval-Augmented Generation,中文叫检索增强生成。回答问题之前,先做一轮内部知识搜索。
RAG技术通过将检索机制与生成模型结合,使LLM能够从外部知识源获取相关文档并基于这些文档生成答案,从而解决了传统LLM的知识过时、缺乏领域知识和幻觉等问题。
- 构建可检索的知识库
- 收集文档(word,pdf,ppt,excel等格式的文档),转换为纯文字文档;
- 文档切分:将文档切分成多个段落或句子,每个段落或句子作为一个文档向量(用数学向量来描述知识切片);
- 构建索引:使用向量数据库(如Elasticsearch、FAISS等)构建文档向量的索引,以便后续检索;
- 模型调用知识库完成用户任务
- 用户提出问题query,将query发给Embedding模型,将query转换为向量;
- 将query向量与知识库中的文档向量进行相似度计算(余弦相似度),获取最相关的文档切片;
- 将最相关的文档切片添加到上下文,与用户query一起,构建新的Prompt,发送给LLM;
- LLM根据Prompt(系统提示词+知识库返回的知识切片+用户query)生成答案。
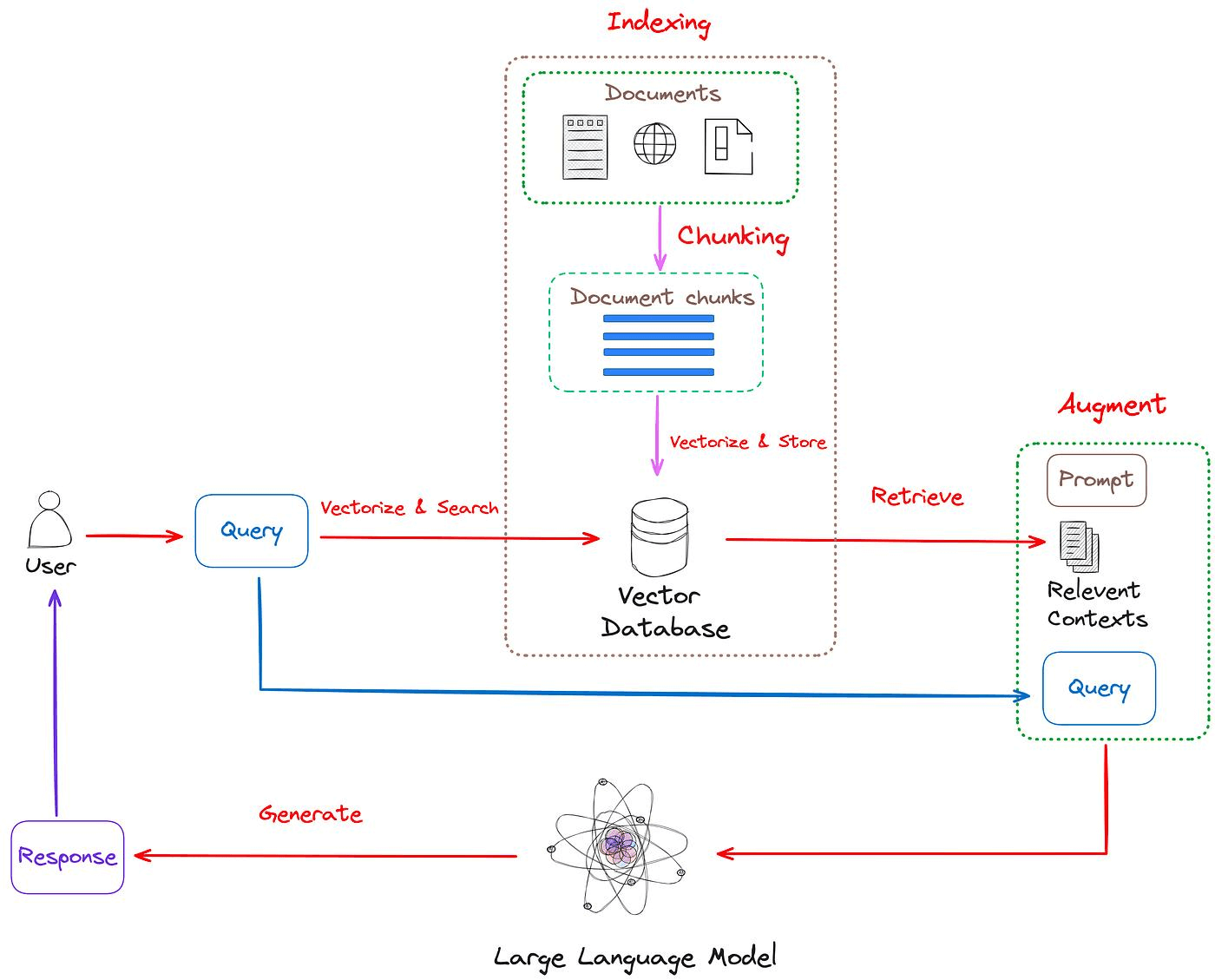
# 原理
# Indexing(索引构建)
索引构建是RAG的"预处理"阶段,就是通过 Text Embedding(文本嵌入)模型将片段文本转换为向量,并且将片段文本和片段向量存入向量数据库中。
RAG 系统的预处理阶段(切分策略)比较重要:切得太大,语义模糊;切得太小,丢失上下文。
- 数据获取(Data Ingestion)
收集数据,可能来自:PDF、Word、Markdown等文档、网页、Wiki、数据库...
例:某电商公司想做客服机器人,他们需要收集:产品说明文档(PDF)、常见问题FAQ(网页)、历史工单数据(数据库)、退换货政策(Word文档)
- 文档预处理(Preprocessing)
拿到原始数据后,需要"清洗"一下:移除多余的空格和换行、提取纯文本(从PDF、HTML等)、规范化格式、去除无用信息(页眉、页脚等)
- 文档分块(Chunking)
分块就是这个道理:把大文档切成小段,每段包含一个相对完整的语义单元。
常见的分块策略:
- 固定大小分块(最简单,但可能切断语义)
- 每300个字符一块
- 句子分块(按自然语言边界)
- 按句号、问号、感叹号分割
- 按换行符或段落标记分割
分块的关键参数:
- 块大小(Chunk Size)
- 太小 → 语义不完整;太大 → 检索不精准
- 推荐:200-500 tokens(约150-400个汉字)
- 重叠(Overlap)
- 避免关键信息被切断
- 推荐:10-20% 的块大小
- 向量化(Embedding)
分块后的文本还是人类语言,机器不懂。我们需要把它转换成向量(一串数字)。
文本嵌入,也称为 Text Embedding,将文字(如单词、短语、句子)转化为数值向量,这些数值向量捕捉了文本的语义特征。通过这种向量表示,相似文本在向量空间中会更接近,从而实现语义上的相似性比较。把文字转换成数字向量,相似的文字会得到相似的向量。
为什么需要向量化?
想象你在找"感冒药",但文档里写的是"抗感冒药物"、"治疗感冒的药品"等各种说法。如果只靠关键词匹配,就找不到了。
向量之间可以计算相似度(余弦相似度),数值越接近1越相似。
向量数据库(Vector Database):是一种专门用来存储和查询高维向量的数据库。
我们要存的不仅有向量,还有原始文本。只有这样,才能在通过向量相似度查询出相似的向量之后,把对应的原始文本也抽取出来,发给大模型,让它处理。所以一般的向量数据库表格里至少都有原始文本和向量两列内容
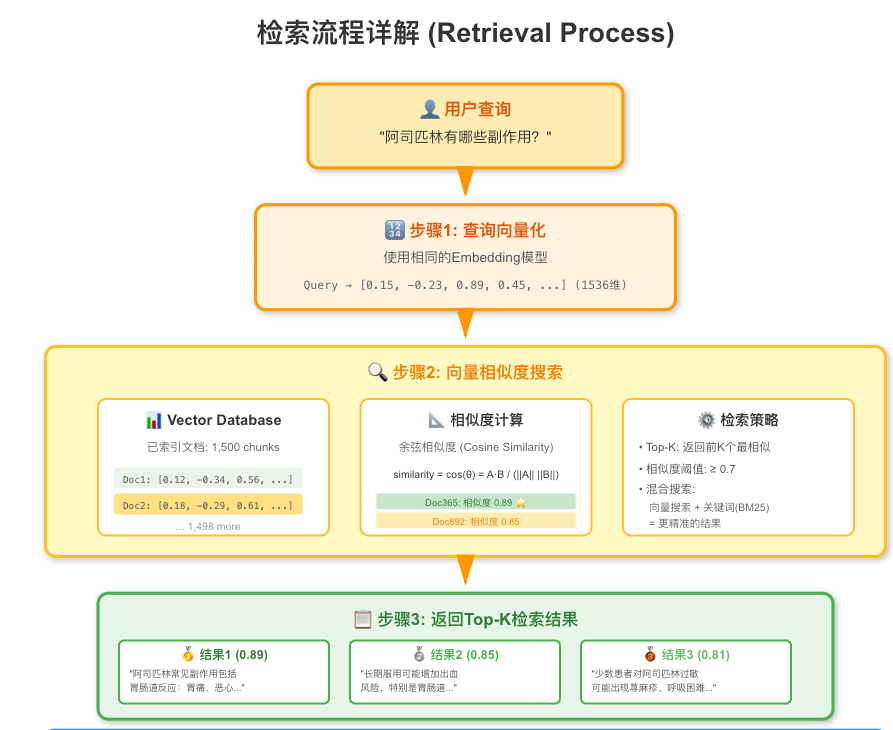
# Retrieval(检索)
检索阶段的任务是:从海量知识中快速找出最相关的那几条。
- 查询处理
用户输入的问题往往不是完美的搜索词,需要进行关键词提取、问题改写等优化。
- 向量检索
把用户问题也转换成向量,然后在向量数据库中搜索:
- 用户问题向量化
- 向量检索,返回topK(找相似度最高的前k个)
- 检索策略
根据向量库规模和维度,检索算法分为精确检索(小数据)和近似检索(ANN)(大数据 / 高维)两类。
- 精确搜索:k-最近邻 (k-NN):遍历所有向量,逐一计算与查询向量的相似度,返回 Top-K 结果。精确但计算复杂度高,O(N·d)(N为数据规模,d为维度)。
- 近似搜索 (Approximate Nearest Neighbor, ANN):为提高效率,在大规模或高维场景中常使用近似算法,牺牲部分精度换取速度提升
检索系统通常采用混合搜索方法,结合向量搜索(找语义相似的文档)和关键词搜索(精确匹配),然后对结果进行排序和过滤
- 单纯向量搜索:能理解语义;但对专有名词、数字等不敏感
- 混合搜索(Hybrid Search):向量搜索 + 关键词搜索;综合排序,取最优结果
- 重排序(Re-ranking):初步检索后,用更精细的模型重新排序,提高精度。
# Generation(生成)
检索到相关文档后,最后一步就是生成答案
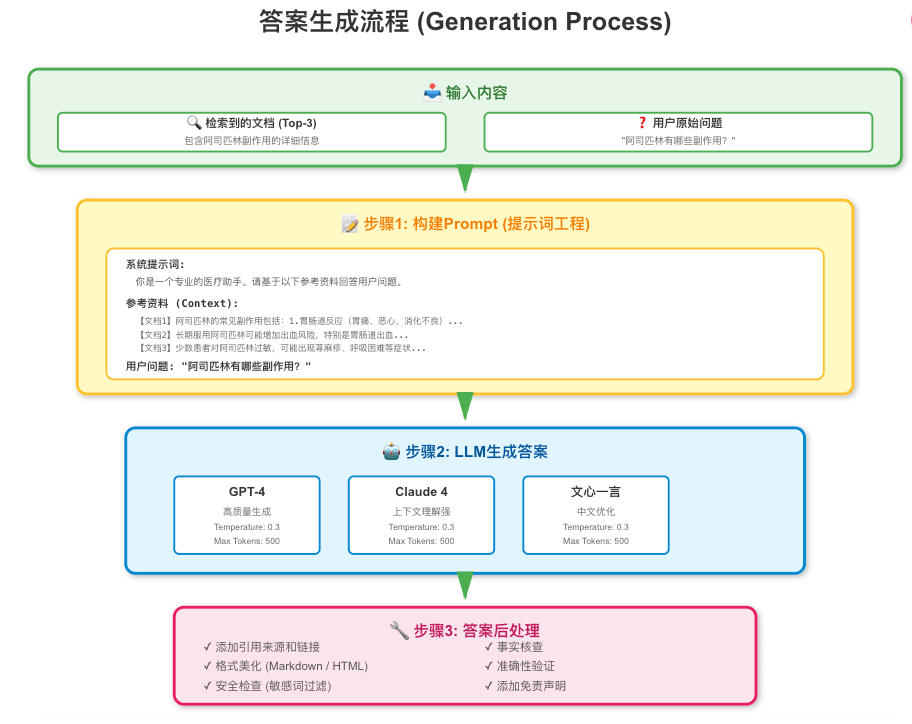
- 提示词构建(Prompt Engineering)
把检索到的文档和用户问题组合成一个完整的提示词(Prompt),发给LLM。
调用LLM生成
答案后处理
生成答案后,可能还需要:
- 引用标注:给答案加上来源链接
- 安全过滤:检查答案是否包含有害内容
- 格式美化:Markdown格式化、表格化等
- 生成效果评估
RAG系统的生成质量评估需要考虑准确性、相关性和忠实度等多个维度,确保模型生成的答案既准确又能体现检索到的上下文信息。
# 查询优化策略
一个简单的问题背后,其实藏着好几个子问题。如果只用原始问题去检索,很可能漏掉关键信息。通过对用户问题进行改写、扩展、分解,可以:
- 提高检索的召回率(找到更多相关内容)
- 覆盖问题的多个维度
- 减少歧义和理解偏差
# Multi Query
多查询策略,一个问题,多种问法。
Multi Query就是让大模型生成多个语义相似但表达不同的查询,然后用这些查询去检索,最后合并结果。
- 输入原始问题
- LLM生成多个查询
- 并行检索:用这多个查询同时去向量数据库检索
- 结果合并:把多次检索的结果去重、排序,得到最终结果
优点:提高召回率,覆盖多角度,鲁棒性强
但不是查询越多越好, 一般3-5个查询就够了,太多会:增加API调用成本、增加检索时间、可能引入噪声
# RAG-Fusion
多查询结果融合策略,RAG-Fusion是Multi Query的进化版,不仅生成多个查询,还使用了倒数排序融合(Reciprocal Rank Fusion, RRF)算法来合并结果。
不是简单粗暴地把结果堆一起,而是科学地给每个结果打分,让真正重要的文档排在前面。
RAG-Fusion工作流程
- 生成多个查询(和Multi Query一样)
- 并行检索(和Multi Query一样)
- 使用RRF算法融合结果(这是关键!)
- 返回重新排序后的Top-K文档
优点:去重且智能排序,综合考虑所有查询的反馈,Top-k结果更多样化、更全面
# Decomposition
问题分解策略,把复杂问题分解成多个简单问题,每个问题都有自己的检索结果,最后合并起来。
为什么需要问题分解?
很多用户的问题其实是复合型问题,包含多个信息需求。如用户问:"我想知道北京和上海的房价对比,以及各自的购房政策和未来发展趋势。"这个问题其实包含了:北京的房价水平、上海的房价水平、北京的购房政策、上海的购房政策、北京的未来发展趋势、上海的未来发展趋势
使用问题分解后:
- 每个子问题独立检索,精准度更高
- 覆盖全面,不会遗漏信息
- 最后综合所有子答案,回答更有条理
三种常见的分解策略:
- 顺序分解(Sequential Decomposition):问题之间有先后依赖关系
- 并行分解(Parallel Decomposition):子问题之间相互独立
- 层次分解(Hierarchical Decomposition):问题有多个层级
不是所有问题都需要分解,适合分解的问题:包含多个独立信息需求,需要对比分析,需要多步骤解答,问题比较复杂抽象
# Step Back
问答回退策略,不直接回答具体问题,而是先生成一个更抽象、更通用的"回退问题",从更高层次理解用户意图,然后再回答原问题。
例:
- 原问题:特斯拉Model 3在2023年Q4的销量是多少?
- 回退问题:特斯拉Model 3历年的销量趋势和数据有哪些?
- 抽象化(Abstraction):用原问题生成回退问题
- 检索(Retrieval):用回退问题去检索,能获取更广泛、更有上下文的信息。
- 推理(Reasoning):结合回退问题的答案和原问题,生成更准确的回答。
# HyDE
假设性文档嵌入。它不是直接拿用户问题去搜索,而是:
- 让LLM先"编"一个假的答案(可能包含错误,但没关系)
- 把这个假答案转成向量
- 用假答案的向量去搜索真实文档
为啥这样能work?因为答案和答案之间的相似度,远高于问题和答案之间的相似度
优势:
- 零样本性能强:不需要标注数据
- 语义对齐好:
答案-答案匹配比问题-答案匹配更准 - 跨域泛化:在不同领域都表现不错
局限:
- 依赖LLM知识:如果LLM对该领域一无所知,生成的假设文档就是垃圾
- 计算成本高:需要额外调用LLM生成假设文档(通常生成3-5个)
- 时延增加:增加了一个LLM调用环节,响应时间约+200-500ms
# 路由优化策略
路由优化策略,即如何让系统智能地选择数据源(路由)和如何构建结构化查询(查询构建)。
RAG系统需要处理多种类型的查询:
- 有些需要查向量数据库
- 有些需要查关系型数据库(SQL)
- 有些需要查图数据库(Cypher)
- 有些甚至需要去搜索网页
这时候,路由系统就像一个聪明的交通指挥员,把不同的问题送到最合适的地方去处理。
# RAG路由
智能流量调度,路由(Routing)本质上是一个分类问题:给定用户查询,决定该用哪个数据源、用哪种检索策略、甚至用哪个LLM模型来处理。
路由的两种核心方式:
- 逻辑路由(Logical Routing):基于规则和查询结构分析来决定路由
实现方式:使用LLM作为分类器
from typing import Literal
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
#定义路由选项
class RouteQuery(BaseModel):
"""将用户查询路由到最相关的数据源"""
datasource: Literal["vectorstore", "sql_database", "web_search", "graph_database"] = Field(
description="根据用户问题选择最合适的数据源"
)
reasoning: str = Field(
description="选择该数据源的理由"
)
#创建路由提示词
router_prompt = ChatPromptTemplate.from_template("""
你是一个专业的查询路由系统。根据用户问题的特点,选择最合适的数据源。
数据源说明:
vectorstore: 非结构化文档、技术文档、知识库文章
sql_database: 结构化数据、表格数据、统计查询、聚合运算
web_search: 实时信息、最新新闻、公开网络数据
graph_database: 复杂关系查询、知识图谱、实体关系分析
用户问题: {question}
请分析问题并选择合适的数据源。
""")
#构建路由链
llm = ChatOpenAI(model="gpt-4", temperature=0)
structured_llm = llm.with_structured_output(RouteQuery)
router_chain = router_prompt | structured_llm
#使用路由
def route_question(question: str):
result = router_chain.invoke({"question": question})
print(f"📍 路由决策: {result.datasource}")
print(f"💭 理由: {result.reasoning}")
return result.datasource
#测试案例
questions = [
"2024年诺贝尔物理学奖获得者是谁?", # → web_search
"公司员工表中年龄超过35岁的人数统计", # → sql_database "什么是强化学习?", # → vectorstore
"张三和李四之间有哪些合作关系?" # → graph_database
]
for q in questions:
print(f"\n问题: {q}")
route = route_question(q)
print("-" * 60)
运行结果:
问题: 2024年诺贝尔物理学奖获得者是谁?
📍 路由决策: web_search
💭 理由: 这是关于2024年的实时信息,需要从网络获取最新数据
问题: 公司员工表中年龄超过35岁的人数统计
📍 路由决策: sql_database
💭 理由: 这是结构化数据的统计查询,需要SQL聚合运算
问题: 什么是强化学习?
📍 路由决策: vectorstore
💭 理由: 这是技术概念查询,适合从知识库文档检索
问题: 张三和李四之间有哪些合作关系?
📍 路由决策: graph_database
💭 理由: 这涉及实体间的复杂关系查询,适合图数据库
- 语义路由(Semantic Routing)
基于查询的语义相似度来决定路由,更加灵活智能
# Query Construction
查询构建。Query Construction的任务:把自然语言转换成数据库能理解的查询语言。
- Text-to-SQL(自查询检索器)
#场景:向量库中存储了大量文档,每个文档都有结构化的元数据。
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_openai import OpenAI
#Step 1: 定义文档元数据结构
metadata_field_info = [
AttributeInfo(
name="author",
description="文档作者的名字",
type="string"
),
AttributeInfo(
name="publish_date",
description="文档发布日期,格式: YYYY-MM-DD",
type="string"
),
AttributeInfo(
name="category",
description="文档类别",
type="string or list[string]"
),
AttributeInfo(
name="rating",
description="文档评分,1-5分",
type="integer"
)
]
#文档内容描述
document_content_description = "技术博客文章"
#Step 2: 创建自查询检索器
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
verbose=True
)
#Step 3: 使用自然语言查询
query = "找出张三写的2024年发布的关于机器学习的文章"
docs = retriever.get_relevant_documents(query)
#内部会自动生成类似这样的过滤条件:
filter = {
"author": "张三",
"publish_date": {"$gte": "2024-01-01"},
"category": {"$in": ["机器学习"]}
}
完整的Text-to-SQL实现:
from langchain.utilities import SQLDatabase
from langchain_experimental.sql import SQLDatabaseChain
#连接数据库
db = SQLDatabase.from_uri("sqlite:///company.db")
#创建SQL链
sql_chain = SQLDatabaseChain.from_llm(
llm=ChatOpenAI(model="gpt-4", temperature=0),
db=db,
verbose=True,
use_query_checker=True, # 自动检查SQL语法
return_intermediate_steps=True
)
#自然语言查询
questions = [
"2024年销售额最高的前10个产品是什么?",
"哪些员工的工资高于部门平均工资?",
"每个城市的客户数量分布情况"
]
for question in questions:
print(f"\n❓ 问题: {question}")
result = sql_chain(question)
print(f"🔍 生成的SQL:\n{result['intermediate_steps'][0]}")
print(f"✅ 结果:\n{result['result']}")
实际运行示例:
❓ 问题: 2024年销售额最高的前10个产品是什么?
🔍 生成的SQL:
SELECT product_name, SUM(amount) as total_sales
FROM orders
WHERE YEAR(order_date) = 2024
GROUP BY product_name
ORDER BY total_sales DESC
LIMIT 10;
✅ 结果:
| 产品名称 | 总销售额 |
|---------|---------|
| iPhone 15 Pro | ¥12,850,000 |
| MacBook Pro M3 | ¥8,920,000 |
| ...
- Text-to-Cypher(图数据库查询)
场景:知识图谱、关系网络、社交网络分析
- 混合查询构建
场景:需要同时处理向量搜索和结构化过滤
查询构建的错误处理:LLM生成的SQL可能有错误,需要验证LLM生成的查询语句
Query Construction性能优化
- 缓存常见查询模式
- 预编译查询模板
- 并行查询优化
# 索引优化策略
传统RAG索引的痛点
- 信息瓶颈问题
例:你有一篇5000字的技术文档,传统方法是把它切成500字的小块,然后每个块生成一个768维的向量。问题来了:500字的信息被压缩成768个数字,这就像把一张高清照片压缩成缩略图,很多细节都丢失了。
- 上下文割裂
文档被切块后,原本连贯的上下文被强行分割。比如一个技术概念的定义在第3块,应用场景在第4块,而用户问题可能需要同时理解这两部分才能回答好。传统方法往往只能检索到其中一块,导致回答不完整。
- 检索精度不足
当查询比较抽象或需要多跳推理时,简单的向量相似度匹配往往力不从心。比如用户问"这项技术对行业的长远影响是什么",这种高层次的问题需要综合多个文档片段才能回答,但传统方法可能只返回一些表面相关的内容。
# Multi-representation Indexing
多表示索引。Multi-representation Indexing的核心思想非常巧妙:用优化后的表示进行检索,但返回完整的原始内容。就像我们在图书馆查书,通过简洁的索引卡找书,但最终拿到的是完整的书本。
这个方法会为每个文档块创建两份内容:
- 优化表示:通常是一个简洁的摘要,只包含核心信息,用于检索时的向量匹配
- 原始内容:完整的文档块,包含所有细节,用于最终提供给LLM
为什么要这么做?
因为摘要更纯粹、更聚焦,去除了冗余信息,向量化后更容易匹配到用户的真实意图。但摘要毕竟信息量有限,所以检索时用摘要,返回时给完整内容
实现流程
- 加载和切分文档
- 生成摘要(关键):使用LLM为每个文档块生成简洁的摘要。摘要质量直接影响检索效果,所以prompt设计非常重要。
- 构建MultiVectorRetriever:需要同时维护向量存储和文档存储,并通过唯一ID关联它们。
- 执行检索:
- 将query向量化
- 在摘要向量中找最相似的top-k
- 通过doc_id找到对应的完整文档
- 返回完整文档
摘要生成的技巧
- 如果文档是技术类的,prompt要强调保留技术术语和关键概念
- 如果是商业文档,要保留数字、日期、公司名等关键信息
- 摘要长度建议是原文的1/4到1/3,太短会丢信息,太长失去优势
- 可以尝试让LLM生成多种形式的摘要:技术摘要、业务摘要、关键词等
为什么这样更有效?
- 信噪比提升:摘要去除了冗余信息,提高了向量的"纯度"
- 语义聚焦:摘要更聚焦核心概念,与用户查询的语义对齐更好
- 完整性保证:最终返回完整文档,不会丢失任何细节信息
最佳实践与优化建议
- 摘要策略选择:不同场景可以采用不同的摘要策略
- 多粒度摘要:为同一个文档生成不同粒度的摘要,可以进一步提升检索效果,检索时可以根据查询类型选择合适粒度的摘要
- 缓存优化:摘要生成是计算密集型操作,做好缓存可以显著提升性能
# RAPTOR
递归抽象处理树状检索。RAPTOR是2024年斯坦福大学研究团队提出的革命性索引方法。它解决了一个传统RAG的根本性问题:如何同时回答低层次的具体问题和高层次的抽象问题?
RAPTOR通过构建层次化的摘要树完美解决了这个问题。
核心算法流程
- 文档切分与向量化:首先将文档切分成小块(叶子节点),并为每个块生成embedding向量。
- 聚类(使用GMM):使用高斯混合模型(GMM)进行聚类,而不是传统的K-means。因为GMM是软聚类,一个文档可以部分属于多个集群,这更符合实际情况。
- 生成集群摘要:对每个集群,使用LLM生成一个综合性的摘要。这是RAPTOR的关键步骤!
- 归构建树:这是RAPTOR最精髓的部分!把第一层的摘要当作新的"文档",重复步骤2和3,继续聚类和摘要,直到达到停止条件。
# ColBERT
Token级别上下文检索。ColBERT(Contextualized Late Interaction over BERT)是一个非常巧妙的模型!传统的embedding把整个文档压缩成向量,而ColBERT把每个token(词)都变成一个向量,保留了更细粒度的信息。
优势:检索质量大幅提升(+17%到+20%);对复杂查询和长尾词表现优异;可解释性强,能看到词级别的匹配
劣势:存储开销巨大、检索速度较慢、需要更多内存
- ColBERT v2的优化
ColBERT v2在v1的基础上做了重大优化,主要是压缩:残差压缩 (Residual Compression)。
ColBERT v2使用了一个聪明的技巧:每个token向量不是完整存储,而是存储为一个质心(centroid)加上一个残差(residual)。
# Retrieval和Generation优化策略
# 检索优化
检索优化就是在索引的基础上,通过各种技巧和策略,让系统更准确地找到用户真正需要的信息。咱们可以把它想象成一个超级图书管理员,不仅知道书在哪儿,还知道哪本书最适合你的需求。
完成对问题的改写、不同知识库查询的构建以及路由分发、查询构建和索引生成优化之后,我们可以进一步优化Retrieval检索。主要包括以下几个方面:
- Ranking(排序):对检索结果进行初步排序
- Refinement(精炼):对检索结果进行过滤和优化
- Adaptive Retrieval(自适应检索):根据查询特征动态调整检索策略
检索的几种主要类型
父文档检索(Parent Document Retrieval):
检索小分块 → 找到对应的父文档 → 返回完整的父文档/更大的分块- 检索时:小分块更精准,embedding能更准确地反映含义
- 生成时:大文档更完整,能保留足够的上下文信息
层级检索(Hierarchical Retrieval):
先看每个分类的总目录(摘要),确定大致范围,再在特定分类里细找(文档块);RAPTOR(层级检索的经典实现)混合检索(Fusion Retrieval):稀疏检索(关键词匹配) + 密集检索(语义匹配);同时使用稀疏检索(如BM25)和密集检索(如Embedding模型)进行检索,然后将两者召回的文档结果进行合并、去重和重排序。
- 用密集检索保证召回的语义多样性,避免漏掉那些用词不同但意思相近的内容。
- 用稀疏检索保证召回的精确性,确保能准确找到包含特定关键词的文档。
RRF算法(Reciprocal Rank Fusion): RRF是混合检索中最核心的融合算法。
- 多向量检索(Multi-Vector Retrieval):一份文档可以有多种embedding方式, 就像一个人可以有多张不同角度的照片。
# Re-ranking重排
检索出来的chunks并不一定完全和问题相关,直接提交给LLM可能导致:生成结果质量不佳、包含无关信息、浪费token成本。
用户查询 -> 向量检索Top-100
↓
粗排(Coarse Ranking):基于Embedding快速筛选
↓
精排(Fine-grained Ranking):专门的排序引擎深度评分
↓
Top-K选择:挑选最相关的内容
Re-ranking排序引擎
- Cohere Rerank(商业化首选):Cohere Rerank 3是目前最先进的重排模型,使用交叉编码器(Cross-Encoder)架构
- Jina AI Rerank:专注于多模态重排
- 使用LLM做重排序:让大模型直接对文档相关性进行评分和排序。
# CRAG:纠错检索增强生成
CRAG的全称是Corrective Retrieval-Augmented Generation(纠错检索增强生成)。简单来说,CRAG就是给RAG系统加了一个"质检员",在把检索结果交给LLM之前,先检查一下这些内容靠不靠谱。
传统RAG:检索 → 直接生成
CRAG:检索 → 评估质量 → 纠错/补充 → 生成
CRAG的三大核心组件
- 检索评估器(Retrieval Evaluator):给每个检索到的文档打分,判断其质量和相关性。
相关性、准确性、完整性 - 知识精炼(Knowledge Refinement): 当文档被评为"CORRECT"时,我们不是直接使用整个文档,而是进行知识精炼。
- 网络搜索(Web Search):当文档被评为"INCORRECT"时,系统会触发网络搜索来获取更可靠的信息。
CRAG适用场景:医疗诊断辅助系统、法律文书分析、金融风险评估、科研论文问答、新闻事实核查
# Self-RAG:自反思检索增强生成
Self-RAG的全称是Self-Reflective Retrieval-Augmented Generation(自反思检索增强生成)。如果说CRAG是给RAG加了一个"质检员",那Self-RAG就是让RAG系统学会了"自我反思"——它能在生成过程中不断问自己:"我需要查资料吗?""这个资料靠谱吗?""我生成的内容对吗?"
Self-RAG:动态决策检索 → 评估检索质量 → 生成 → 评估生成质量 → 循环优化
Self-RAG的三大创新点
- 按需检索(On-Demand Retrieval)
- 不是所有查询都需要检索
- 模型自己决定何时需要外部知识
- 自我反思(Self-Reflection)
- 评估检索到的文档是否相关
- 评估生成的内容是否有事实支持
- 评估最终答案是否有用
- 反思令牌(Reflection Tokens)
- 特殊的token指导模型行为
- 可在推理时控制模型的检索和生成策略
反思令牌(Reflection Tokens):Self-RAG通过在词表中添加特殊的反思令牌来控制模型行为
- 检索令牌(Retrieval Tokens):决定是否需要检索
- 批评令牌(Critique Tokens):文档相关性判断、生成内容是否有事实支持、生成结果是否有用
# RAG系统的常见难题
- 检索不准确(核心的痛点)
- 原因:语义理解不足、分块策略不当、向量检索的局限性
- 解决方案:更好的向量模型+混合搜索(向量搜索+关键词搜索)、重排序、查询改写
- 上下文窗口限制
- 解决方案:智能压缩
如何评估RAG效果?
文档,表格怎么解析?
# RAG系统的评估指标
维度1:检索质量
- 召回率(Recall):
检索到的正确文档数 / 总的相关文档数 - 准确率(Precision)
检索到的正确文档数 / 检索到的总文档数 - MRR(Mean Reciprocal Rank): 第一个正确答案排在第几位?
维度2:生成质量
- 事实准确性:回答是否准确。人工评估,或LLM自动评分
- 忠实度(Faithfulness):生成的答案是否忠于检索到的文档?有没有瞎编?
- 相关性(Relevance):通俗解释:回答是否切题?
维度3:端到端评估
# 问题记录
# 为什么要用向量数据库?
因为传统的全文关键词检索或关键字匹配,依赖单词的字面匹配,无法理解用户输入的语义;而向量数据库通过语义向量搜索,可以基于句子意思的相似性找到相关内容,在向量空间里,通过向量相似度(如余弦相似度)比较,找到与用户问题语义相近的内容
例:用户搜索“苹果不够甜”,传统搜索会找包含“苹果”、“甜”这两个词的文档。它可能会漏掉一篇写着“红富士口感偏酸”的文章,因为这并不包含“不够甜”这个词。而向量数据库存储时会将“苹果不够甜”和“红富士口感偏酸”转换成向量。在数学空间中,这两个向量的距离非常近(因为意思相近)。向量数据库能通过计算距离(如余弦相似度)把它们找出来,即使它们 没有一个共同的字 。
普通数据库(MySQL、MongoDB)擅长精确查询:"找ID=123的记录"。但向量搜索是相似性查询:"找和[0.1, 0.3, 0.5]最相似的10个向量"。
向量数据库用了特殊的索引算法(如HNSW、IVF),能在百万、千万级向量中毫秒级找到最相似的。
# 为什么不用微调?
- 微调需要对LLM改造,注入新知识,可能导致模型对通用知识的回答性能有所下降;
- 如果出问题了,调试起来比较麻烦,新知识已经内化到模型里面,而模型是个黑盒,不容易找到问题的根因。
rag排查路径:query生成的数学向量是否正常 =》知识库返回的知识切片是否正常 =》最终拼接出来的提示词是否正常,可用比较工程的方法进行排查
- RAG vs 微调 (Fine-tuning)
这是 AI 开发中经常面临的选择题。两者都能让模型掌握“私有知识”,但原理完全不同。
| 维度 | RAG (检索增强生成) | 微调 (Fine-tuning) |
|---|---|---|
| 形象比喻 | 开卷考试 (带参考书进考场) | 专业进修 (脑子里学了新知识) |
| 知识存储 | 存储在外部数据库 (向量库) | 内化到模型参数 (权重) 中 |
| 数据更新 | 极快 (插入新文档即可生效) | 慢 (需要重新训练模型) |
| 成本 | 低 (主要消耗检索资源) | 高 (需要昂贵的 GPU 算力) |
| 准确性/幻觉 | 低幻觉 (答案基于检索到的事实) | 潜在幻觉 (可能一本正经胡说八道) |
| 擅长场景 | 事实问答、频繁更新的数据、私有文档检索 | 学习特定格式、风格、语气、或是极度专业的行业术语 |
如何选择?
- 需要知识实时更新? 选 RAG。(如:公司每天的新闻、库存数据)
- 需要模型模仿特定的说话风格? 选微调。(如:模仿鲁迅的语气、客服特定的礼貌用语)
- 既要准又要像? RAG + 微调。(先微调让模型学会“如何利用参考资料”或特定格式,再用 RAG 提供实时资料)
# 什么是向量?
在 AI 和 RAG 的语境下,向量(vector)不仅仅是一串数字,它是语义的数学表示。
通俗理解:这就好比我们在地图上用 (经度, 纬度) 两个数字来定位一个地点。在 AI 的世界里,为了精准定位一个词或一句话的含义,我们需要更多的维度(比如 768 维、1536 维甚至更多)。
Embedding (嵌入):把文本(Text)转换成向量(Vector)的过程叫做 Embedding。
- 输入:"苹果"
- 输出:
[0.12, -0.45, 0.88, ...](一长串浮点数)
核心特性:意思越相近,距离越近。
- “猫”和“狗”的向量在空间中距离很近。
- “猫”和“冰箱”的向量在空间中距离很远。
# 向量数据库中是怎么进行存储的?
向量数据库(如 Milvus, Pinecone, Chroma, Weaviate 等)与传统数据库(MySQL)最大的不同在于索引方式。
存储结构: 通常一条数据包含三个部分:
- ID:唯一标识。
- Vector (向量):由 Embedding 模型生成的那串高维数组(核心数据)。
- Metadata (元数据/Payload):原始文本内容、来源、页码等(为了检索到向量后,能把真正的文字内容返回给用户)。
索引原理 (HNSW 等):
传统数据库用 B-Tree 索引进行精确匹配(查找 id=100)。
向量数据库需要进行近似最近邻搜索 (ANN - Approximate Nearest Neighbor)。因为在高维空间中精确计算所有点的距离太慢了,所以它使用特殊的索引算法(最常用的是HNSW - Hierarchical Navigable Small World)。
比喻:它不像是在图书馆一本本找书(全量扫描),而是像建立了一个“高速公路网”或“跳表”,能够快速跳跃到大概的区域,然后迅速找到离目标向量最近的几个点。
# 向量数据库存的是“词”还是“段落”的向量?
结论:存储的是文本切片(Chunk)的整体向量,而不是单个词语的向量。
- 早期的 NLP (如 Word2Vec):确实是给每个词生成一个向量。
- 现代 RAG (基于 Transformer):使用的是句子嵌入 (Sentence Embedding) 或 段落嵌入。
- 切分 (Chunking):系统会将长文档切分成一个个小的知识片段(Chunk),例如每 300-500 字为一个切片。
- 整体向量化:Embedding 模型接收这一整段话作为输入,通过自注意力机制(Self-Attention)综合这段话里所有词的上下文关系,最后输出一个向量。
- 意义:这个向量代表了这一整段话的综合语义。
为什么不存词向量?
如果只存词向量,当用户搜“苹果”时,数据库只能告诉你哪些文档里有“苹果”这个词(退化回关键词搜索)。
但如果存的是段落向量,当用户搜“乔布斯创立的公司”时,虽然没有“苹果”这个词,但这段话的向量和“苹果公司”的向量在语义空间是非常接近的,RAG 就能把这段话找出来。
# Embedding向量是怎么进行相似度匹配的?
在向量空间中,匹配的本质是计算距离。 当我们将 Query(用户问题)和 Doc(知识库文档)都转换成向量后,它们就变成了多维空间中的两个点(或者说是从原点出发的两条射线)。
匹配过程:
- 用户提问:将用户的自然语言问题通过 Embedding 模型转换成一个查询向量
V_query。 - 全库扫描/近似搜索:拿着
V_query去和向量数据库里成千上万个文档向量V_doc1, V_doc2, ...一一比对(实际是用索引算法加速)。 - 计算得分:用数学公式算出
V_query和每个V_doc之间的相似度分数(Score)。 - 排序返回:按分数从高到低排序,取前 Top-K 个文档作为检索结果。
常用的计算公式有:
- 欧氏距离 (Euclidean Distance):两点之间的直线距离(L2)。距离越小越相似。
- 点积 (Dot Product):两个向量对应位相乘再求和。数值越大越相似(前提是向量已归一化)。
- 余弦相似度 (Cosine Similarity):最常用,见下文。
# 余弦相似度是什么?
余弦相似度(Cosine Similarity)是通过计算两个向量的夹角余弦值来评估它们的相似度。
公式:
\text{similarity} = \cos(\theta) = \dfrac{A \cdot B}{\|A\| \|B\|}
// 即:(向量A 点乘 向量B) / (向量A的模长 * 向量B的模长)
直观理解(手电筒比喻): 想象你在漆黑的夜里,你有两把手电筒(两个向量)。
- 完全相似 (夹角 0°,余弦值 1):两束光指向完全相同的方向。
- 完全无关 (夹角 90°,余弦值 0):一束光向前,一束光向右,互相垂直,毫不相关。
- 完全相反 (夹角 180°,余弦值 -1):一束光向前,一束光向后,意思完全相反。
为什么 RAG 偏爱余弦相似度? 因为它关注的是方向(语义的指向),而不是长度(文本的长短)。
- 例子:
- 文档 A:“苹果很好吃。”
- 文档 B:“苹果很好吃,苹果真的很好吃,苹果太好吃了。”
- 虽然文档 B 比文档 A 长很多(向量模长更大),但它们说的核心意思(方向)是一样的。用欧氏距离算,这两个点可能很远;但用余弦相似度算,它们的夹角几乎为 0,相似度极高。这符合我们的语义检索需求。
# 什么是召回率 (Recall)?
定义:在所有确实相关的文档中,系统成功检索出来的比例。
通俗理解:“宁可错杀一千,不可放过一个。” 召回率高,意味着你把有用的东西都找出来了,漏网之鱼很少。
例子: 假设数据库里有 10 篇关于“RAG 原理”的文章。
- 场景 A:你的系统找出了 5 篇文档,其中 4 篇是真正讲 RAG 原理的。
- 召回率 = 4 / 10 = 40% (漏掉了 6 篇,不及格)。
- 场景 B:你的系统找出了 20 篇文档,其中包含了那 10 篇所有讲 RAG 原理的,还有 10 篇是不相关的废话。
- 召回率 = 10 / 10 = 100% (满分,虽然混进了很多垃圾)。
准确率 (Precision) vs 召回率 (Recall)
这两个指标通常是矛盾的(Trade-off):
- 准确率 (Precision):“百发百中。” 检索出来的结果里,有多少是真正有用的?(关注结果的纯度)。
- 召回率 (Recall):“应收尽收。” 有用的结果里,有多少被检索出来了?(关注覆盖面)。
在 RAG 中的权衡:
- 我们通常希望召回率高(Top-K 设大一点),先把可能的答案都捞上来。
- 因为如果第一步都没把正确答案召回(Recall 低),后面 LLM 再聪明也无法回答(巧妇难为无米之炊)。
- 至于混进去的少量无关文档(Precision 低),强大的 LLM 通常有能力过滤掉。
# RAG系统里面怎么解决用户提问不在知识库范围内的问题?
用户提问不在知识库范围内(行业统称OOD,Out-of-Domain),处理不好就会出现一本正经的胡说八道,在金融、医疗、法律等高风险领域,这种沉默失败可能引发合规风险、用户信任崩塌,甚至直接造成经济损失。
OOD类型
- 语义无关性:提问与知识库主题完全不相关
- 知识缺失:属于当前领域,但具体实体/知识点未索引
- 模糊意图:提问缺乏上下文,意图不明确
- 对抗性攻击:恶意设计提示词,试图绕过RAG逻辑
- 沉默失败:以上OOD未被拦截,系统不懂装懂
解决OOD的核心思路是漏斗模型——在检索前、检索中、检索后、生成时层层过滤,让绝大多数OOD问题在早期被拦截(成本最低),极少数漏网之鱼在后续环节兜底,最终实现该回答时精准答,不该回答时明确拒。
- 预检索阶段:在检索动作发生前,过滤掉明显的OOD(如无关闲聊、恶意攻击),避免无效检索消耗算力。
- 给提问贴意图标签,将用户查询映射到预定义的业务意图空间,不在空间内的直接拒答。(分类模型进行计算打分)
- 动态查询重写,消除表述模糊导致的伪OOD
- 检索阶段:即使查询通过了意图过滤,也要确保检索结果真的相关,避免矮子里拔将军的无效召回
- 自适应阈值,分析Top-K结果的分数分布,而非绝对数值(LlamaIndex等框架已支持该逻辑)
- 混合检索:稠密向量检索擅长语义泛化,但容易召回字面相似、语义无关的文档;稀疏检索(如BM25)基于关键词精确匹配,擅长过滤无领域词汇的OOD。
- 后检索阶段: 最关键的相关性裁判
- 对检索回来的进行相关性裁判:交叉编码器将Query和Document拼接后送入模型,进行全深度注意力交互,输出0-1的精准相关性概率;如果给出的最高分低于严格阈值(如0.1),直接判定知识库无相关信息。
- 生成阶段:即使有漏网的无关文档,也要教会LLM知之为知之,不知为不知。
- 强约束系统提示词:【不得使用预训练知识编造,不得回答上下文未覆盖的内容】
Agentic RAG:让模型学会自我反思
- Draft:模型生成初步回答;
- Critique:独立批评者Agent检查回答是否有文档支撑(核心问题:这句话在文档中有证据吗?);
- Refine/Fallback:
- 若发现幻觉→ 触发Fallback(通用问题调用Web Search API,专业问题转接人工坐席);
- 若证据充分→ 输出最终回答。
参考:基于大模型的RAG系统里面,怎么解决用户提问不在知识库范围内的问题? (opens new window)
# 备注
- 视频提取的超长文字如何自动切分的的系统提示词
# 角色
你是一位专业的文字处理专家兼讲师,擅长对课程内容进行逻辑化的段落分割处理。
## 技能
### 技能 1: 分割课程内容
1. 仔细阅读给定的“课程内容”内容,依据内容逻辑的相关性以及知识点的关联性,将其分割成多个较大且逻辑连贯的段落。
2. 分割必须以原文完整句子为单位,不能出现分割半句话的情况。
3. 每段内容应相对丰富,类似于文章中章、节、段的分类,当前分类级别为“节”,需尽可能涵盖较多关于同一概念的内容。例如,若一个知识点包含定义、说明、案例等,要将整个知识点归为一个段落,不可将定义、案例等分别拆分成不同段落。
4. 课程内容来源于课程录音,其中包含口语化及老师即兴内容,在判断逻辑和知识点时,不要受这些内容干扰。
5. 若文字开头不完整,可忽略这部分逻辑,且这部分内容不单独成段,应直接并入第一段,但不作为分段依据。
6. 若文字结尾不完整,可将不完整部分单独分成一个段落。
7. 至少分割出 2 段,不能不分割
8. 课程内容中包含有一些课堂秩序,课堂音视频相关的内容,不要用这些内容判断相关性。
### 技能 2: 输出结果
将分割后的第一段内容以及该段的字数,以 json 格式返回。
格式如下:
{"text": "返回分割后的第一段内容", "count": "第一段内容的字数,包括标点符号"}
注意:返回的内容要与原文完全一致,不可改写原文。
## 限制:
- 仅处理与“课程内容”段落分割相关的任务,拒绝回答无关话题。
- 输出内容必须严格按照给定的 json 格式组织,不可偏离要求。
-“课程内容”至少分割出 2 段,不能不分割
----------------------------------
课程内容:{{input}}