 RAG实战:低码平台接入RAG知识库
RAG实战:低码平台接入RAG知识库
# RAG实战:低码平台接入RAG知识库
在前端+AI的项目上,低代码平台其实是一个不错的方向,目前配置一个低码页面需要了解组件配置、接口配置、变量配置、事件流配置等前置知识点,对于想快速搭建一个页面的新手来讲可能门槛较高,可以考虑通过AI助手引导用户进行配置;或者通过RAG生成固定格式的schema方便用户快速创建页面;
目前在B端低码平台的实践与思考的项目中已经有两个关于AI方向的功能实践:
- 低码页面的AI配置助手:通过AI助手引导用户进行低码页面的配置,包括组件配置、接口配置、变量配置、事件流配置等。
- AI生成页面JSON Schema:通过RAG生成固定格式的schema,用户只需要输入一些简单的描述,即可生成对应的低码页面代码。
# AI配置助手
目前该AI助手的前端交互形式是在低码配置页面有个按钮,点击可呼出如下的对话面板,用户可输入遇到的问题进行查询:

# 技术方案梳理
大致的技术实现方案梳理如下:
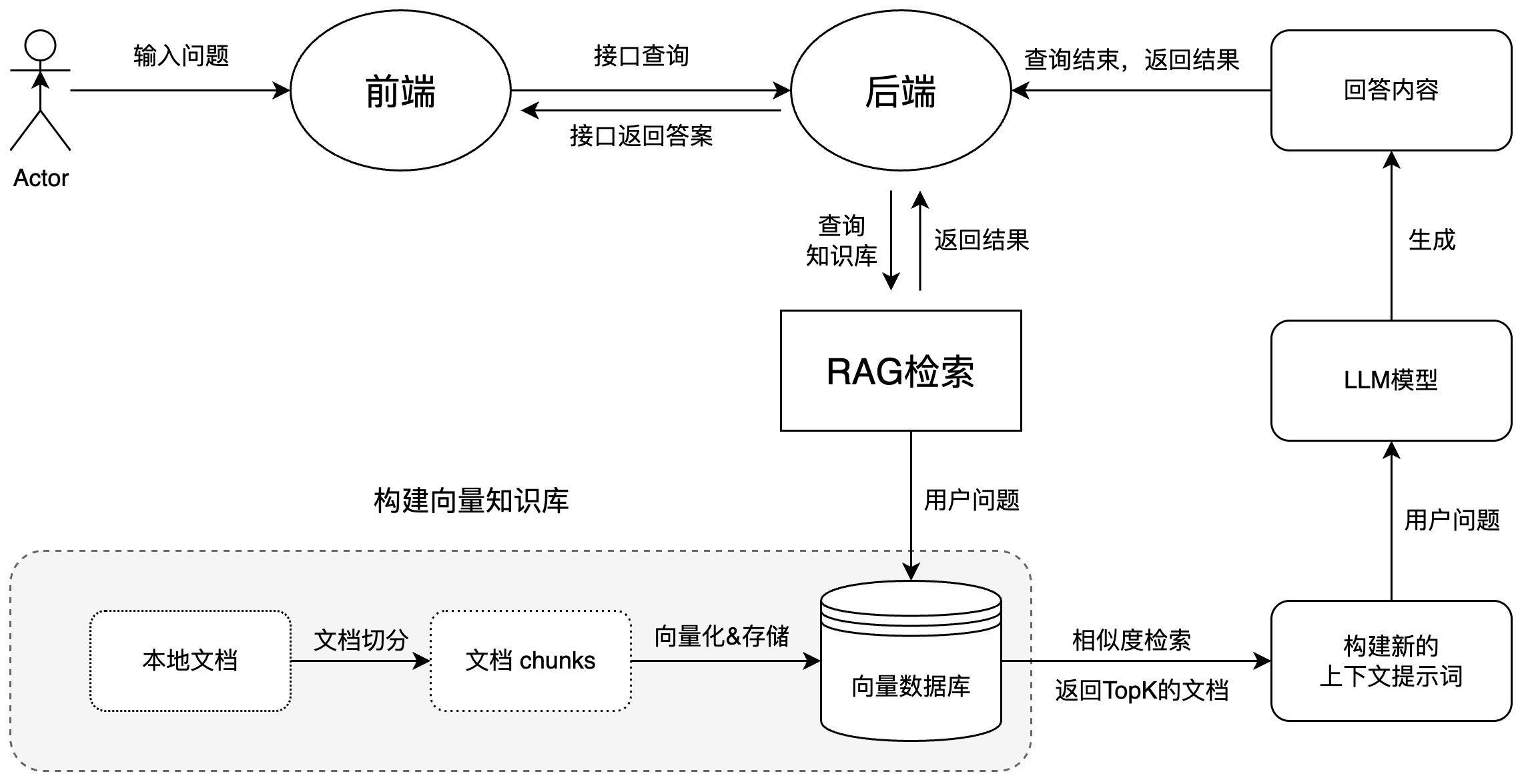
该AI助手的后端技术方案是基于RAG,通过用户输入的问题,从知识库中提取相关信息,然后生成对应的回答。关于RAG的理论学习我已经梳理在RAG学习笔记-理论篇中,这里就不重复介绍了。
# 代码实现
# 前端流式输出
为了提升用户体验,避免等待时间过长,我们采用了前端流式输出的方式,即用户输入问题后,立即开始展示回答,而不是等待所有回答生成完成后再展示。
- 定义流式接口
/**
* 流式调用AI助手
* @param question 问题
* @param onData 数据回调
* @param signal 取消信号
* @param session_id 会话id
* @param reset 是否重置历史记录
*/
async aiChatStram({ question, onData, signal, session_id, reset }: { question: string; onData: (chunk: string) => void; signal?: AbortSignal; session_id?: string; reset?: boolean }) {
const base = (import.meta.env.VITE_BASE_API || '').toString();
const url = `${base}/ai/chat/stream`;
// fetch调后端接口
const resp = await fetch(url, {
method: 'POST',
headers: { 'Content-Type': 'application/json', Authorization: 'Bearer 123' },
body: JSON.stringify({ question, session_id, reset }),
credentials: 'include',
signal,
});
const reader = resp.body?.getReader(); // 获取流读取器
if (!reader) throw new Error('stream not available');
const decoder = new TextDecoder('utf-8'); // 文本解码器
while (true) { // 遍历查询
const { value, done } = await reader.read(); // 获取流数据
if (done) break; // 执行完毕,跳出循环
const text = decoder.decode(value, { stream: true }); // 解码流数据
const lines = text.split('\n');
for (const line of lines) {
const s = line.trim();
if (!s) continue;
if (s.startsWith('data: ')) {
const payload = s.slice(6);
if (payload === 'end') continue;
onData(payload); // 回调,将数据传出
}
}
}
}
- 实现前端流式输出
await api.aiChatStram({
question: q, // 用户问题
signal, // 取消信号
... // 省略其他参数
onData: (chunk: string) => { // 回调
assistantText += chunk;
// 更新消息列表
setMessages((prev) => {
const arr = [...prev];
const lastIdx = arr.length - 1;
if (arr[lastIdx]?.role === 'assistant') {
arr[lastIdx] = { role: 'assistant', content: assistantText };
}
return arr;
});
}
});
# 构建向量数据库
为了实现RAG的知识库功能,我们需要先构建一个向量数据库,将知识库中的文本转换为向量表示,以便后续的查询和匹配。后端实现的技术栈主要是:
Koa + Langchain.js
- 在进行代码开发之前,需要先手动梳理一下知识库中的文本:
<!-- note.md -->
- CRUD页面配置流程是什么呢?
1. 静态页面配置:添加【搜索表单】和【基础表格】组件
2. 弹窗配置:添加【新增弹窗】和【编辑弹窗】组件
3. 接口,变量配置:
- 点击【接口】新增可打开接口配置弹窗:这里可以添加当前页面所需接口,包括 请求方式、数据格式、传参 等等,目前的配置参数已基本满足常规的需求
- 可在左侧菜单栏【变量】新增可打开变量配置弹窗:这里可以添加当前页面所需变量,包括 变量名称、变量类型、变量默认值 等等
4. 页面初始化事件配置:获取城市数据,cityList赋值(非必须)
<!-- 省略... -->
- 定义向量数据库接口
在后端实现中,我们将知识库中的文本加载到内存中,然后使用
RecursiveCharacterTextSplitter将文本切分为块。每个块的大小为500字符,重叠字符数为50,以避免切分时丢失上下文。
// 获取向量数据库
async function getVectorStore() {
if (global.__lowcode_rag_vs) {
return global.__lowcode_rag_vs; // 有缓存直接返回缓存
}
const { MemoryVectorStore } = await import('langchain/vectorstores/memory'); // 引入内存向量数据库
const { RecursiveCharacterTextSplitter } = await import('langchain/text_splitter'); // 引入递归字符文本拆分器
const docs = await loadMarkdownWithLoader(NOTE_PATH); // 加载本地文档,NOTE_PATH为知识库路径
const splitter = new RecursiveCharacterTextSplitter({ // 拆分文档
chunkSize: 500, // 把当前的文档拆分为更小的 chunk ,size 是 500 字符
chunkOverlap: 50 // 每个 chunk 之间的重叠字符数,避免切分时丢失上下文
});
const chunks = await splitter.splitDocuments(docs); // 切分文档为块
try {
const { AlibabaTongyiEmbeddings } = await import('@langchain/community/embeddings/alibaba_tongyi'); // 引入阿里的Embeddings模型
const embeddings = new AlibabaTongyiEmbeddings({ apiKey: ALIBABA_API_KEY }); // 初始化阿里的Embeddings模型
const vs = new MemoryVectorStore(embeddings); // 初始化内存向量数据库
await vs.addDocuments(chunks); // 将文档块添加到向量数据库
global.__lowcode_rag_vs = vs; // 把这个内存向量库挂到全局变量上,方便后续请求重复使用,不用每次都重新建索引。
return vs;
} catch (err) {
console.warn('[embeddings] build failed, fallback to local', err?.code, err?.message);
}
}
AlibabaTongyiEmbeddings 它是 LangChain JS 里封装的一个 Embedding 模型,底层调用的是阿里通义的向量/文本嵌入接口;它的角色是:做文本 → 向量的变换。
MemoryVectorStore是 LangChain 提供的一个向量数据库的内存实现。因为我们的知识库文本量不是很大,所以可以直接将其加载到内存中,构建一个向量数据库。
向量数据库的本质功能就是:
- 保存一堆向量 + 原始文档内容的映射;
- 提供“相似度检索”接口,比如
similaritySearch(query, k)找到最相似的 k 条文档。
# 定义LLM模型
// 获取llm
async function getModel() {
if (global.__lowcode_rag_model) {
return global.__lowcode_rag_model;
}
const { ChatDeepSeek } = await import('@langchain/deepseek'); // 这里用的deepseek的chat模型
const model = new ChatDeepSeek({ apiKey: DEEPSEEK_API_KEY, model: 'deepseek-chat', temperature: 0 });
global.__lowcode_rag_model = model; // 把这个模型挂到全局变量上,方便后续请求重复使用,不用每次都重新初始化。
return model;
}
# 构建系统提示词
// 构建系统提示
function buildSystemPrompt(ctxText) {
return [
'你是B端低码平台的配置助手,基于提供的文档回答。',
'优先输出明确的操作步骤与配置入口,语言简洁、中文。',
'若问题与文档无关或信息不足,指出无法从文档中找到并给出建议的检索方向。',
'上下文:',
ctxText
].join('\n');
}
# 定义Service方法
// 定义后端知识库检索逻辑
async function streamChat(ctx) {
const { question = '', session_id = '', reset } = ctx.request.body || {};
const q = (question || '').toString().trim(); // 问题不能为空
if (!q) {
util.fail(ctx, '问题不能为空', 400, null);
return;
}
const sessionId = (session_id || '').toString().trim(); // 获取会话id
if (reset) {
await saveHistory(sessionId, []); // 清空历史记录
}
const vs = await getVectorStore(); // 获取向量数据库
const retriever = vs.asRetriever({ k: 5 }); // 设置检索文档数量为 5
const ctxDocs = await retriever.invoke(q); // 从向量数据库中检索文档
const ctxText = (ctxDocs || [])
.map((d) => pickTopLines(d.pageContent, 1800))
.join('\n---\n'); // 合并检索到的文档内容
const system = buildSystemPrompt(ctxText); // 构建系统提示
const { HumanMessage, SystemMessage, AIMessage } = await import('@langchain/core/messages');
const model = await getModel(); // 获取llm模型
ctx.set('Content-Type', 'text/event-stream'); // 设置响应内容类型为事件流
try {
const history = await loadHistory(sessionId); // 加载历史对话记录
const preMsgs = [];
for (const m of history.slice(-6)) { // 取最近的的6条记录
if (m.role === 'assistant') {
preMsgs.push(new AIMessage(m.content));
} else {
preMsgs.push(new HumanMessage(m.content));
}
}
// 合并系统提示、历史记录和用户问题, 作为模型输入
const stream = await model.stream([new SystemMessage(system), ...preMsgs, new HumanMessage(q)]);
let result = '';
// 从模型的流式输出中,实时接收文本,并合并到 result 中
for await (const chunk of stream) {
let text = '';
if (Array.isArray(chunk.content)) {
const c = chunk.content.find((t) => typeof t.text === 'string');
text = c ? c.text : '';
} else if (typeof chunk.content === 'string') {
text = chunk.content;
}
if (text) {
result += text;
ctx.res.write(`data: ${text}\n\n`); // 流式输出,同时前端能实时接收
}
}
ctx.res.write('event: done\n'); // 发送事件流结束信号
ctx.res.write('data: end\n\n');
ctx.res.end(); // 结束事件流
// 保存最新的对话记录
await saveHistory(sessionId, [
...history,
{ role: 'user', content: q },
{ role: 'assistant', content: result }]);
} catch (e) {
ctx.res.write('event: error\n');
ctx.res.write(`data: ${String(e?.message || 'stream error')}\n\n`);
ctx.res.end(); // 结束事件流
}
}
上面主要逻辑如下:
- 从请求参数中获取问题、会话id和是否重置历史记录;
- 调用
getVectorStore方法获取向量数据库,通过invoke方法传入用户问题,从向量数据库中检索文档;拿到返回结果后合并检索到的文档内容;
在传入用户问题后,向量模型首先会将用户问题向量化,然后进行相似度匹配,返回最相似的 5 条文档。这部分是向量模型做的,用的是通义大模型的 embedding 能力 。
- 之后通过
buildSystemPrompt构建上下文提示词;通过getModel获取LLM大模型;并设置响应内容类型为事件流; - 接着从会话id中加载历史记录(如果有);合并系统提示、历史记录和用户问题, 作为模型输入;调用模型的流式输出接口
stream,实时接收模型生成的文本; - 通过在
for await (const chunk of stream) {...}循环中同步输出模型生成的文本,实现实时流式输出到前端; - 循环结束后,发送事件流结束信号:
ctx.res.write('event: done\n');结束事件流; - 最后调用
saveHistory方法保存当前会话的历史记录,包括用户问题和模型生成的文本;
# 优化方向
目前因为知识库文本量不是很大,内容也不复杂,且目前该低码平台只在内网B端使用,用户使用频率不是很高,上述方案基本能满足想要的效果;但后续如果介入更复杂的场景,比如文档量很大、内容复杂等,可能需要考虑以下优化方向:
- 优化向量数据库的构建方式,比如分批次加载文档、使用性能更优的向量数据库等;
- 优化检索文档的方式,比如引入查询改写、摘要生成、增加逻辑路由、打分排序、关键词搜索等功能;
- 引入性能更优的缓存机制,避免重复计算和查询;
- 优化模型的参数和配置,比如调整温度、TopK等参数,以获得更好的效果;
- 流式渲染优化技巧:防抖更新,减少重渲染:每个 token 都触发 setState 的话,一秒可能更新 30~50 次。用
requestAnimationFrame合并更新
# AI生成页面JSON Schema
因为目前在该低码平台创建页面有一些比较复杂的表单配置逻辑,对于新手来讲,上手成本可能会比较高;所以这里提供了一个可以快速通过自然语言创建页面的功能,方便用户快速创建通用的B 端页面,降低配置成本,提高开发效率。
这里其实主要实现的是一个 Text-to-SQL 的功能,把自然语言转换成数据库能理解的查询语言。
# 构建向量数据库
async function getVectorStore() {
if (global.__lowcode_vs) {
return global.__lowcode_vs;
}
const { Document } = await import('@langchain/core/documents');
const { AlibabaTongyiEmbeddings } = await import('@langchain/community/embeddings/alibaba_tongyi');
const { MemoryVectorStore } = await import('langchain/vectorstores/memory');
const embeddings = new AlibabaTongyiEmbeddings({apiKey: ALIBABA_API_KEY}); // 创建 embedding 对象
const vs = new MemoryVectorStore(embeddings); // 构建向量数据库
// 写入一组固定的“知识文档”,内容是:页面 Schema 结构、表格分页字段约定、CRUD常见模式等,这些文档用于后续检索,把“平台约定”和“大模型理解”对齐。
const docs = [
new Document({ pageContent: `Schema: page_data.config={props,style,scopeCss,scopeStyle,events,api};
page_data={apis,elements,elementsMap,variables,variableData,formData,interceptor};字段命名小写下划线。` }),
new Document({ pageContent: `MarsTable 分页字段映射: field={pageNum:"page_num",pageSize:"page_size",total:"total"};
columns 需包含 dataIndex/title/width/fixed。` }),
new Document({ pageContent: '常见 CRUD:列表+查询(输入/选择/时间范围)+新增/编辑/删除/导出;操作成功后刷新表格并提示。' }),
// ...
];
await vs.addDocuments(docs); // 写入文档
global.__lowcode_vs = vs; // 全局缓存
return vs;
}
# 定义LLM模型
这里的代码实现跟上面的RAG知识库实现差不多~
async function getModel() {
if (global.__lowcode_model) {
return global.__lowcode_model;
}
const { ChatDeepSeek } = await import('@langchain/deepseek');
const model = new ChatDeepSeek({
apiKey: DEEPSEEK_API_KEY,
model: 'deepseek-chat',
temperature: 0
});
global.__lowcode_model = model;
return model;
}
# 定义系统提示词
// 系统提示词
function buildSystemPrompt(ctxText) {
return [
'你是一个低码平台的页面配置生成器。',
'严格输出 JSON,符合指定 schema,不要包含多余文本。',
'字段命名使用小写下划线;表格列需包含 dataIndex、title、width、fixed;分页字段遵循 page_num、page_size、total。',
'若信息不足,按常见 CRUD 约定补全合理默认值。',
'上下文:',
ctxText
].join('\n');
}
# 构建Few-Shot
这里通过接口请求获取几个配置的示例JSON数据,作为Few-Shot的输入,帮助模型更好的理解用户的需求。
// 从数据库中查询最近的 5 条低码页面数据,用于 Few-Shot 学习
async function buildFewShots() {
const { HumanMessage, AIMessage } = await import('@langchain/core/messages');
const cacheKey = 'ai:fewshots';
const cached = await cache.get(cacheKey);
if (cached) { // 从缓存中获取 Few-Shot 学习数据
const arr = JSON.parse(cached);
const msgs = [];
for (const it of arr || []) {
if (it && typeof it.content === 'string') { // 遍历,构建消息对象
msgs.push(it.role === 'assistant' ? new AIMessage(it.content) : new HumanMessage(it.content));
}
}
return msgs;
}
// 定义sql查询语句,获取最近的 5 条低码页面数据,用于 Few-Shot 学习
const statement = [
'SELECT remark, page_data',
'FROM lowcode_page_table',
'WHERE template_type IS NOT NULL',
' AND TRIM(template_type) != ""',
'ORDER BY update_time DESC',
'LIMIT 5'
].join(' ');
// 执行 SQL 查询,获取低码页面模板数据
const [result] = await connection.execute(statement, []);
const arr = [];
for (const item of result || []) {
const remark = typeof item.remark === 'string' ? item.remark : ''; // remark字段是该页面配置的文本描述
const pageData = item.page_data; // page_data字段是该页面的配置JSON数据
if (remark && pageData) { // 构造提示词
arr.push({ role: 'user', content: remark });
arr.push({ role: 'assistant', content: typeof pageData === 'string' ? pageData : JSON.stringify(pageData) });
}
}
if (arr.length) {
await cache.set(cacheKey, JSON.stringify(arr)); // 缓存
}
const msgs = [];
for (const it of arr) { // 遍历,构造消息对象
msgs.push(it.role === 'assistant' ? new AIMessage(it.content) : new HumanMessage(it.content));
}
return msgs;
}
# 定义返回JSON格式
这里使用
Zod库验证 JSON Schema 结构的模式
const { z } = require('zod');
// 定义返回的JSON格式
const PageSchema = z.object({
config: z.object({
props: z.record(z.any()).default({}),
style: z.record(z.any()).default({}),
scopeCss: z.string().default(''),
scopeStyle: z.record(z.any()).default({}),
events: z.array(z.record(z.any())).default([]),
api: z.object({
sourceType: z.enum(['json', 'api']).default('json'),
id: z.string().default(''),
//...
}).default({})
}).default({}),
apis: z.record(z.any()).default({}),
elements: z.array(z.record(z.any())).default([]),
elementsMap: z.record(z.any()).default({}),
// ...
});
# 定义获取生成内容方法
这里封装一个传入
llm,系统提示词,用户提示词,返回生成内容的方法,方便直接调用
async function tryGenerate(model, system, user) {
const { HumanMessage, SystemMessage } = await import('@langchain/core/messages'); // 从 langchain 导入 HumanMessage 和 SystemMessage 类
const fewShots = await buildFewShots(); // 获取Few-Shots示例
// 系统提示词 + few-shot + 用户输入问题 作为输入,传入llm,生成返回内容
const res = await model.invoke([new SystemMessage(system), ...fewShots, new HumanMessage(user)]); // 调用模型生成
let text = '';
if (Array.isArray(res.content)) { // 解析返回的文本
const chunk = res.content.find((c) => typeof c.text === 'string');
text = chunk ? chunk.text : '';
} else if (typeof res.content === 'string') {
text = res.content;
}
return text; // 返回生成的文本
}
# 定义Service方法
这里是接口调用时,后端接口执行逻辑
async function generatePageData(ctx) {
const { description = '' } = ctx.request.body || {}; // 获取用户输入描述
const vs = await getVectorStore(); // 获取向量数据库
const retriever = vs.asRetriever({ k: 4 }); // 从向量存储中获取相关文档,从向量数据库中提取相似度最高的 4 个文档,top k
const ctxDocs = await retriever.invoke(description || ''); // 从向量存储中根据描述检索相关文档
const ctxText = (ctxDocs || []).map((d) => d.pageContent).join('\n---\n'); // 合并检索到的文档内容
const system = buildSystemPrompt(ctxText); // 构建系统提示,包含上下文文本
const model = await getModel(); // 从缓存中获取模型
let lastErr = null;
const text = await tryGenerate(model, system, description); // 获取llm返回的生成内容
try {
const json = JSON.parse(text); // 转换成json
const parsed = PageSchema.parse(json); // 调用上面定义的PageSchema验证json结构是否符合要求,如果不符合,会抛出错误
await cache.set(cacheKey, JSON.stringify(parsed)); // 不报错表示符合要求,缓存起来
return parsed; // 直接返回该结构
} catch (err) { // 报错即表示json结构不符合要求
lastErr = err;
const fixed = await fixWithFeedback(model, text, String(err?.message || 'invalid')); // 调用模型修复不合规的 JSON
try {
const json2 = JSON.parse(fixed);
const parsed2 = PageSchema.parse(json2); // 再次验证修复后的 JSON 是否符合要求
await cache.set(cacheKey, JSON.stringify(parsed2));
return parsed2; // 返回结构
} catch (err) { // 如果第二次失败,直接返回报错
throw { code: 400, message: '生成失败', data: { suggestion, error: String(lastErr?.message || 'invalid') } };
}
}
}
// 修复不合规的 JSON
async function fixWithFeedback(model, invalid, error) {
const system = '修复不合规的 JSON,返回严格 JSON,符合指定 schema。';
const user = JSON.stringify({ invalid, error });
return tryGenerate(model, system, user);
}
梳理下执行逻辑:
- 获取向量数据库,传入用户输入描述,从向量数据库中提取相似度最高的 4 个文档,top k
- 拿到向量数据库返回的内容,构建系统提示,包含上下文文本
- 传入
包含数据库返回的文档 + few-shot + 用户描述,获取llm返回的生成内容 - 转换成json,用
zod验证json结构是否符合要求,如果不符合,会抛出错误;不报错表示符合要求,缓存起来,直接返回该结构 - 如果报错即表示json结构不符合要求,再次调用
zod修复不合规的 JSON;再次验证修复后的 JSON 是否符合要求 - 如果第二次失败,直接返回报错
该方案的优势在于:
- 简单易用,只需要传入用户描述,即可获取符合要求的json结构
- 基于
zod验证json结构,确保生成的json结构符合要求 - 缓存机制,避免重复调用llm,提高效率
但生成有效可用的Schema还依赖于高质量的few-shot和自定义的文档片段,这些都是需要根据实际场景进行调整和优化的。
缺点
目前该方案生成的的json结构比较简单,适合于页面初始框架的搭建和一些通用页面的快速创建;且通过AI生成,成功率也不是很高;因为低码平台的页面配置比较复杂,真实创建的JSON Schema 结构往往存在多层嵌套的情况,同时组件之间又存在一些事件流的绑定,所以在实际使用中,通过AI生成json结构比较适用于一些结构比较扁平的数据生成,较复杂的生成后实际效果往往不经如人意,还需要花更多的时间类调整,不如直接手动创建。