 LLM大模型原理学习笔记
LLM大模型原理学习笔记
# LLM大模型原理学习笔记
# 神经网络
# 模型
模型就是一个数学公式。设计模型,就是设计能解决真实问题的数学公式
最常见的模型,分类问题
- 输入:给定一组符合要求的输入数据(需要判断类别)
- 已知:类别总数为n(n选1)
- 输出:经过一系列数学公式计算后,输出n个概率,分别代表属于某类别的概率
如何设计一个模型
- 确定数学公式的过程
- 公式:y = ax + b
- 参数:a = 50, b = -100
当问题复杂到无法用简单的线性公式解决时,需要设计更复杂的公式。
神经网络结构的数学公式:模拟人脑,设计一种一劳永逸的公式结构
# 神经元
单个神经细胞只有两种状态:兴奋和抑制
网络中的每个节点(神经元)接收输入信号,如果所有信号的加权总和超过一个“阈值”,它就被“激活”(兴奋),并向下传递信息;否则就保持“抑制”。
这种简单的开关机制,构成了整个网络决策和学习的根本。
多个神经元按层排列,构成网络。
# 激活函数
神经元的开关机制是通过通过激活函数来实现的。一个神经元就是一个决策小单元。它接收很多上游传来的信号,同时它需要做一个“决定”:我收到的这些信息足够重要吗?我需要把这个信息继续往下传递吗?,激活函数就是这个决策的“开关” 。它将所有输入信号的加权总和作为输入,然后输出一个值。
最简单的激活函数(阶跃函数)就像一个纯粹的开关:输入总和超过阈值,就输出1(兴奋=>传递);否则输出0(抑制=>不传递)。
整个神经网络由无数个神经元组成。当这些成千上万的简单决策汇集在一起时 => 整个网络就能做出极其复杂的决策。
神经网络中的神经元接受上一层神经元的输出值作为输入值;输入层神经元节点会将输入属性值直接传递给下一层;在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数。
激活函数是贴在神经元输出端的非线性函数,使神经网络能够拟合非线性关系。常见的有 ReLU、Sigmoid、Tanh 等。如果没有激活函数,无论多少层网络都等价于线性变换,表达能力有限。
# 神经网络
人的大脑有大约860亿个神经元,它们互相连接,传递信息。神经网络就是模仿这个原理。一个神经元的工作原理:
- 接收信号:从其他神经元接收电信号
- 处理信号:把这些信号加起来
- 决定是否激活:如果信号够强,就"点亮",传给下一个神经元
神经网络(Neural Network)是一种受人脑神经元结构启发的计算模型。它由大量人工神经元相互连接而成。 它可以从数据中学习输入到输出的映射关系。神经网络的“学习”过程就是不断调整神经元之间的连接权重。
为LLM提供了基本的计算框架。LLM使用的是神经网络中一种叫 Transformer 的特定架构。
神经元是最基本的计算单元:接受输入 =》 加权求和 =》激活 =》 输出
深度神经网络: 多层结构的神经网络,多层结构可以提取更深层的特征。一个神经元只能做简单判断,但把成千上万个神经元连起来,分成好几层,就能处理超级复杂的任务。典型的三层结构:
- 输入层:接收原始数据
- 隐藏层:进行复杂计算(可以有很多层)
- 输出层:给出最终结果
人工神经元中的激活函数一般由简单的线性模型 + 非线性函数组成;非线性赋予神经网络拟合复杂模式的能力。
Q:什么是神经网络的非线性变换?
非线性变换 (Non-linear Transformation) 是神经网络能变聪明的关键。
如果没有非线性变换(即激活函数),无论神经网络叠加多少层,它本质上还是一个简单的线性方程($y = ax + b$)。
- 线性 :一条直线。只能切一刀(分类)。
- 非线性 :这就好比把直线“掰弯”了。通过无数次弯曲,它可以拟合出任意复杂的形状(比如人脸的轮廓、语言的逻辑)。
激活函数(Activation Function) 就是那个负责“掰弯”的工具。通过层层“掰弯”,神经网络就能拟合出任意复杂的曲线和形状,从而理解这个复杂的世界。激活函数引入了非线性,让神经网络可以学习复杂的模式。
常见激活函数
ReLU (Rectified Linear Unit), GELU (Gaussian Error Linear Unit) , Sigmoid, Softmax, tanh...
神经网络的前向传播:
- 初始化网络
- 定义激活函数
- 前向传播:前向传播比较简单,就是向量点乘(即加权求和),然后经过一个激活函数。最终输出预测结构。
梯度消失(Vanishing Gradient)
当梯度小于1时,预测值与真实值之间的误差每传播一层会衰减一次,如果在深层模型中使用sigmoid作为激活函数,这种现象尤为明显,将导致模型收敛停滞不前。当层数增多时,小于1的值不断相乘,最后就导致梯度消失的情况出现。
梯度爆炸 (Exploding Gradient)
梯度在传播途中变得越来越大,最后变成无穷大(NaN)。
激活函数的特点
- 激活函数的特点是非线性,而数据的分布绝大多数是非线性的 => 可以强化网络的学习能力
- 不同的激活函数特点不同,应用也不同
- sigmoid和tanh函数输出值在(0,1)和(-1,1)之间 => 适合处理概率值;会产生梯度消失 => 不适合深层网络训练
- ReLU的有效导数是常数1,解决了深层网络中出现的梯度消失问题 => 更适合深层网络训练
- 编写一个神经网络
- 定义网络结构(输入层、隐藏层、输出层),定义每层的神经元
- 初始化模型参数
- 循环操作
- 前向传播:输入数据通过网络,计算输出。
- 计算损失:对比输出与真实值,计算误差(损失)。
- 反向传播:从输出层向输入层,计算每个参数的梯度(误差对参数的导数)。
- 参数更新:根据梯度,使用优化算法(如梯度下降)更新参数,使损失减小。
- 迭代:重复以上步骤,直到损失足够小或达到最大迭代次数。
数据决策AI => 自定义神经网络,结构相对简单,输出结果比较稳定
生成式AI => AI大模型(基于神经网络,transformer)
- MNIST
MNIST(Mixed National Institute of Standards and Technology database):包含了70,000张手写数字的图像,每一张都是28x28像素的灰度图像,其中60,000张用于训练,10,000张用于测试,每张图像的内容只包含一个手写数字,从0到9的其中一个数字。
任务:给定一张
28x28像素的灰度图像,经过一系列数学公式计算后,输出10个概率,分别代表该图像中的内容是0-9某个数字的概率
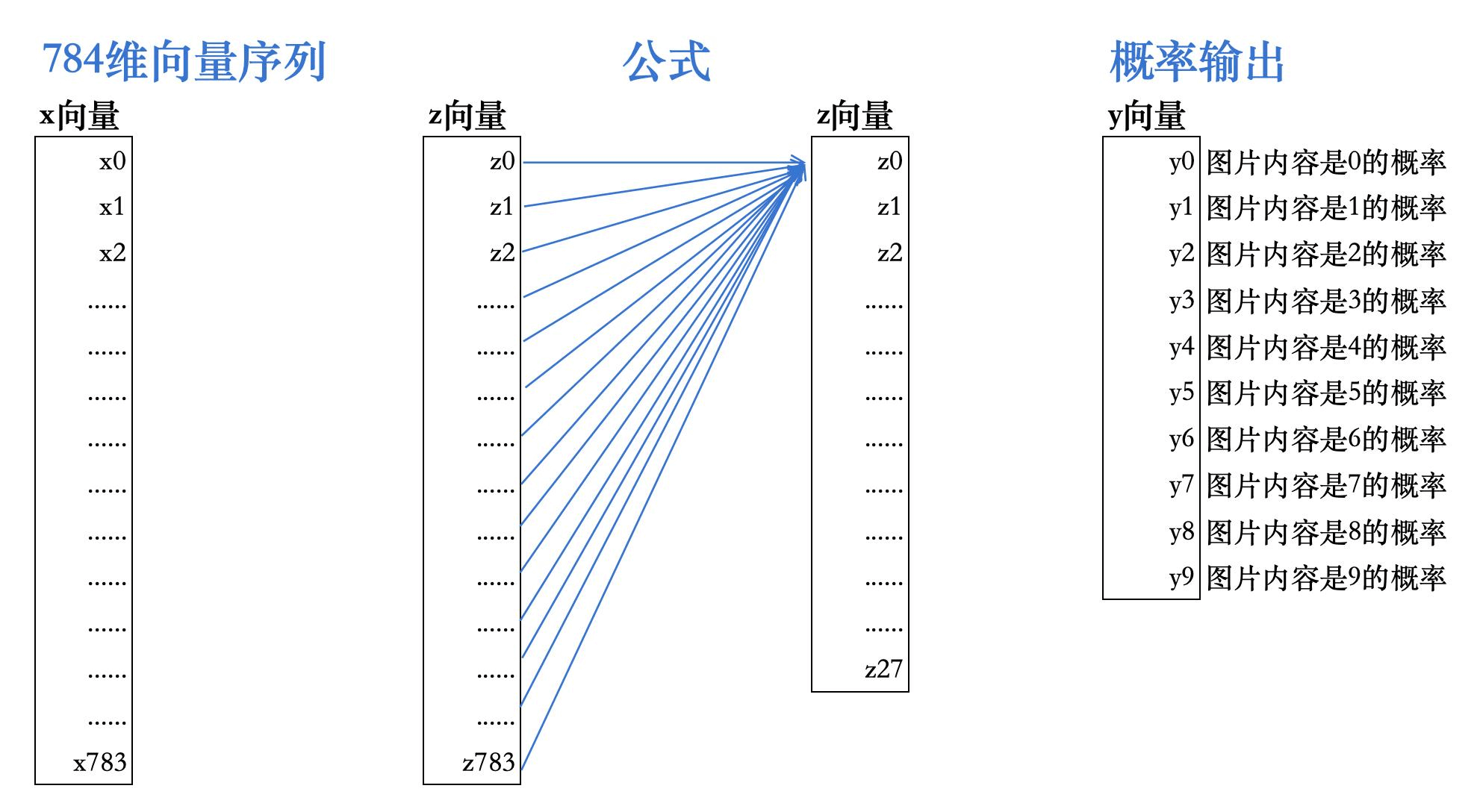
刚才MNIST的那个网络有多少个参数?28*28*785 + 28*785 + 10*29 = 637,710
GPT有多少个参数?GPT-3和InstructGPT都是1750亿参数,GPT-4大概1.8万亿参数
# 反向传播
反向传播 (Backpropagation) 是神经网络知错能改的关键机制。
反向传播就是通过链式法则,从最终结果开始,一层层地向后计算每个节点、每个参数对最终结果的 “影响力”(即梯度)。在真实的神经网络中,计算出这个“影响力”后,就可以根据它来微调参数(这就是“学习”的过程)。
反向传播是神经网络训练的核心算法,用来告诉模型你哪里错了,怎么改。简单来说:
- 前向传播 (Forward) :模型做题。数据从输入层一层层传到输出层,模型给出一个预测结果(比如预测它是“猫”)。
- 计算损失 (Loss) :拿预测结果和真实标签(标准答案)对比,算出误差(Loss)。
- 反向传播 (Backward) : 从输出层往回推,一层层计算每个神经元对这个误差“贡献”了多少。
权重矩阵在反向传播的过程中同样扮演着传递的作用。前向传播:传递输入信号;反向传播:传递输出的误差
# 机器学习
确定数学公式的过程
- 设计公式:有了神经网络,设计公式结构轻松多了(人类设计的公式融合神经网络)
- 确定参数:求助机器学习
机器学习(Machine Learning, ML):通过计算机完成大规模数学计算,以找到相对更优的参数组合的过程,就叫做机器学习,也就是我们所说的模型训练。
机器学习是人工智能的一个分支,让计算机从数据中自动学习规律,而不是通过硬编码规则。主要分为监督学习、无监督学习、强化学习等。
让计算机从数据中学习,而不需要显式编程,而是通过从数据中学习规律和经验,从而完成特定任务(如识别图片、翻译语言、下棋)的科学。
从一个最简单的神经网络开始,模拟整个机器学习的过程
例:公式:y = ax + b;参数:确定a和b分别是多少?
- 随机初始化一组(a,b),比如a=3,b=-5
- 在训练数据集中,利用y = ax + b 进行分类
- 计算分类结果的误差(损失函数)
- 计算a和b的值应该如何变化可以减小误差
- 计算出一组新的(a,b)值
- 回到步骤2
模型训练、模型学习、机器学习:目标就是要想办法得到一组a和b的值,使总误差最小化。
什么是损失函数 (Loss Function)?
它是衡量模型预测值和真实值之间差距的数学公式。用来衡量模型预测值与真实值不一致的程度,是一个非负实数函数。
- 通俗理解:它就像考试后的“扣分机制”。
- 如果标准答案是 100,模型猜 99,差距小,扣分少(Loss 小)。
- 如果标准答案是 100,模型猜 10,差距大,扣分多(Loss 大)。
- 训练目标:让 Loss 越小越好(无限接近于 0)。
- 常见类型:
- MSE (均方误差):预测房价等数值时用,
(预测值 - 真实值)^2。- Cross Entropy (交叉熵):预测分类(如是猫还是狗、下一个词是什么)时用。LLM 训练主要用这个。
训练MNIST神经网络,训练一个模型,识别手写数字
- 公式:一个多层神经网络
- 参数:637,710个参数
- 随机初始化一组参数
- 在训练数据集中,利用神经网络进行分类
- 计算分类结果的误差
- 计算637,710个参数的值应该如何变化可以减小误差
- 计算出一组新的参数值
- 回到步骤2
# 从模型到机器学习
如果我们把 AI 比作“解一道超级复杂的数学题”,那么:
- 模型 (Model) = 没写完的公式
- 概念:模型就是一个待定系数的数学架构。
- 例子:最简单的模型是直线方程
y = ax + b。- 这里,
x是输入(比如房子面积),y是输出(比如房价)。 a和b是参数 (Parameters),目前还是未知的,可以是任意数。
- 这里,
- 神经网络 (Neural Network) = 超级复杂的套娃公式
- 概念:现实世界太复杂了(比如识别图片、理解语言),简单的直线方程根本描述不了。于是我们模仿人脑神经元,把成千上万个简单的公式连在一起,层层嵌套,形成一个深度神经网络。
- 本质:它依然是一个数学公式,只是参数变得极其庞大(GPT-4 有 1.8 万亿个参数)。
- 状态:在没训练之前,这 1.8 万亿个参数都是随机生成的数字,所以它现在是个“傻子”。
- 机器学习 (Machine Learning) = 暴力破解求参数
- 概念:机器学习就是填空题。我们的目标是找到那 1.8 万亿个参数的最佳组合,让公式算出来的结果和真实结果最接近。
- 流程:
- 瞎猜:先随机填一组参数。
- 考试:拿数据去测(Forward Propagation),看预测结果和真实结果差多少(计算 Loss)。
- 改错:根据差距,反向推导(Back Propagation),把每个参数都微调一点点,让下次误差小一点。
- 循环:重复上述过程几千亿次,直到误差小到无法再小。
总结:
深度学习 = 用“神经网络”这种复杂的结构(模型),通过“机器学习”这种暴力试错的方法(算法),从海量数据中“学”出一组最优的参数(权重)。
# 深度学习(DL)
Deep Learning,定义:是机器学习的一个子集,使用深层神经网络(通常有多层)来学习数据的表示。深度学习模型可以自动从原始数据中学习层次化的特征。
关键:使用神经网络,尤其是深度神经网络(多个隐藏层)。深度学习通过堆叠多层自动提取层次化特征,在图像、语音、文本等领域取得突破。
例子:卷积神经网络(CNN)用于图像,循环神经网络(RNN)用于序列,Transformer用于自然语言处理。
# 强化学习(RL)
Reinforcement Learning,是机器学习的一个分支,关注的是智能体(agent)如何在环境(environment)中采取行动(action)以最大化累积奖励(reward)。
- 机器学习是总称,包括深度学习、强化学习以及其他方法。
- 深度学习是一种使用深层神经网络的机器学习方法,可以用于
监督、无监督和强化学习。 - 强化学习是一种学习范式,智能体通过与环境的交互来学习,通常用于序列决策问题。
强化学习可以与深度学习结合,形成深度强化学习,以处理复杂问题。
# RLHF
RLHF(Reinforcement Learning from Human Feedback),基于人类反馈的强化学习,是大模型对齐的关键技术,完美体现了深度强化学习的应用:
RLHF流程中的神经网络:
┌── 基础模型:大型Transformer神经网络(作为策略网络)
├── 奖励模型:另一个Transformer神经网络(学习人类偏好)
└── PPO算法:使用这两个神经网络进行优化
具体过程:
1. SFT模型(策略网络)生成回答
2. 奖励模型(价值网络)评估回答质量
3. PPO使用奖励信号更新策略网络(大模型)
4. 大模型参数被微调,生成更符合人类偏好的回答
这就是深度强化学习:策略(大模型)和价值函数(奖励模型)都用神经网络表示,通过交互(生成回答-获得评分)来优化策略。
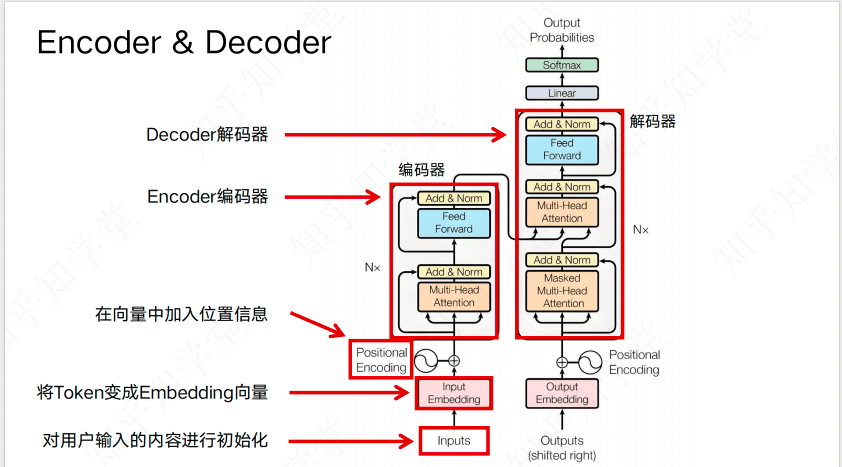
# Transformer架构
Transformer一种基于自注意力机制的神经网络架构,完全摒弃了 RNN 的循环结构,通过并行计算处理序列。它由编码器和解码器组成,核心是自注意力层和前馈网络。Transformer 是大语言模型(LLM)的基础架构,如 GPT、BERT 等。
Transformer架构
- Tokenization - 文本变成Token
- Embedding - Token变成向量
- Positional Encoding - 在向量中加入位置信息
- Encoder & Decoder - 深度理解语义
- Linear - 生成“下一个字”的权重分布
- Softmax - 将权重分布转换成概率分布
# Tokenization
文本变成Token, 对用户输入的内容进行初始化。
把一段文字,变成一组Token,也就是词元化(Tokenization)
子词(subword)词元化
⽐如:
- "subword"这个词,可以拆分成"sub"和"word"两个⼦词
- "encoded"可以拆解为"encod"+"ed"
- "encoding"可以拆解为“encod”+"ing"
OpenAI的官网上,1000 Tokens大概是750个英文单词上下(500个汉字上下)。
为什么一个字不是一个Token呢?
这是一个效率与语义的平衡问题。
如果按字切 (Character-level):
- 例子:"Apple" ->
A,p,p,l,e(5个Token) - 问题:太碎了。
- 导致序列极长,浪费 LLM 宝贵的上下文窗口(Context Window)。
- 单个字母
p很难包含什么明确的语义,模型学习难度大。
- 例子:"Apple" ->
如果按词切 (Word-level):
- 例子:"Apple" ->
Apple(1个Token) - 问题:词表爆炸。
- 英语有几十万个单词,还在不断造新词。如果遇到训练时没见过的词(Out of Vocabulary),模型就无法处理。
- 例子:"Apple" ->
最优解:Subword (子词切分,如 BPE)
- 策略:“常见词整体切,生僻词拆开切”。
- 例子:
- "Data" ->
Data(常见,1个Token) - "Databricks" ->
Data,bricks(合成词,拆成2个Token)
- "Data" ->
- 优势:
- 词表大小可控(通常 5万-10万)。
- 序列长度适中。
- 永不遇到生词:即使是乱码,也能拆成一个个字母,模型总能读进去。
Token化非常有利于减少词表的数量(Token的总数少于文字的总数)。
# Embedding
Token变成向量。
向量、空间、特征
什么是向量?
1维向量:坐标 [ 3 ],一维空间中的一个点
2维向量:坐标 [ 2, 5 ],二维空间中的一个点
3维向量:坐标 [ -1, 4, -2.5 ],三维空间中的一个点
...
... 512维向量:坐标 [ 3, 5, -2, ...... ],512维空间中的一个点
...
... 1024维向量:坐标 [ 6, 1.2, -2, ...... ],1024维空间中的一个点
...
...
one-hot编码的一些问题
- 维度过高,过于稀疏:容纳3000个汉字就需要30003000的映射表,容纳5000个汉字则需要50005000的映射表
- 没有体现出“距离”概念:如果两个字之间的意思相近,那两个对应的向量求“距离”的时候,就应该更相近
- 没有数学或逻辑关系:最好能满足:
国王 - 男人 + 女人 = 女王
Embedding
专门把Token映射到新的数学空间,每个Token都能通过Embedding模型,映射到新的数学空间中的一个点(向量)
向量化需要神经网络生成对应维度的参数
2017年的经典Transformer,向量维度:512维
2018年的GPT,向量维度:768
2019年的GPT-2,向量维度:1600
2020年的GPT-3,向量维度:12288维
2024年的Llama 3,向量维度:16384维
比如,我,【7, 4, 6, -2, 11, -1.2, 6.3, 0.56, ......】总计12288个坐标数值
- 计算语义相似度(距离)
- 数学或逻辑计算
前面的两个步骤,假设对话中有650个字,GPT会把对话中的650个字转换成大概1300个Token,然后再把1300个Token变成1300个Embedding向量,每个向量12288维。
# Positional Encoding
在向量中加入位置信息。
一句话的语义除了取决于文字外,还受文字位置的影响
上一步中的650个字转化出来的1300个向量,每个向量都只表示了一个文字,还需要加入位置信息
Input[0] = Embedding[0] + Position[0]
Input[1] = Embedding[1] + Position[1]
Input[2] = Embedding[2] + Position[2]
...
Input[i] = Embedding[i] + Position[i]
...
Input[1299] = Embedding[1299] + Position[1299]
一个段落里包含丰富的语义,每一个细节的语义都可能影响问题的回答。
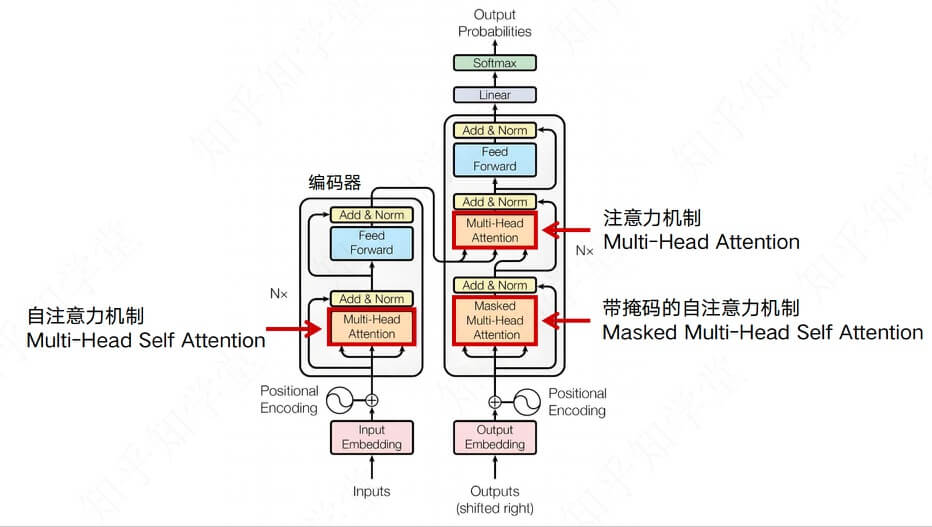
# Encoder & Decoder
编码器 & 解码器。
- Encoder流程
机器是同时看所有词,想要理解段落语义,需要做数学向量之间的加减法
假设我们有一个段落,包含1000个Token:
[你好,我是,一个,学生,你好,我是, 一个, 老师, ...]
第一轮信息聚合:每一个Token转换之后的向量(Token语义信息+位置信息)都作为一个中心主题词,与其他所有的Token做数学向量的加减计算,去聚合信息,去得到一个新的向量。
一轮之后,1000个向量都变成了新的1000个向量,但每个向量都包含了丰富的信息
第二轮信息聚合:新的1000个向量重新依次作为中心主题词,依次进行信息聚合;但这一次就是短语和短语之间做信息聚合,会得到新的1000个向量,每个向量都包含了丰富的信息。
.......
经过很多轮信息聚合后,Encoder会输出1000个向量,每个向量都包含了丰富的信息。之后就把这些向量交给Decoder。所以理论上编码器只做一次计算输出向量后,就可以把这些向量交给Decoder。
- Decoder流程
- 首先解码器接收到编码器传过来的1000个向量,同时会输入一个表示开始生成的特殊Token向量,表示可以开始生成了;
- 之后解码器第一轮会基于传入的1000个向量,以及特殊Token向量,去预测下一个向量是什么。
- 之后解码器第二轮会基于传入的1000个向量,以及上一轮预测出的Token向量,去预测下一个向量是什么。
- 重复以上过程,直到输入一个特殊的表示结束的Token向量,表示生成结束。
Encoder一般用来做分析:人类的文字 =》 向量
Decoder一般用来做生成:向量 =》 预测下一个向量
Encoder做信息聚合可以把当前向量跟段落所有向量做加减计算,去加权聚合信息,去得到一个新的向量。但Decoder只会把当前向量跟之前所有的向量做加权聚合。
Q: 为什么向量要用上万维的数学向量来表示一个Token?
因为向量信息聚合过程中,向量会聚合到当前段落越来越丰富的信息,现在的大语言模型能够支持的上下文都是几百万Token,为了在信息聚合后一个向量能够包含这几百万Token的信息,所以向量维度要设置的非常高。
- Decoder-Only
因为Decoder会Encoder的工作,后来最新的大语言模型,几乎都采用了 Decoder-Only 的架构
GPT系列: GPT-2、GPT-3、GPT-4、ChatGPT用的不是完整的Transformer,而是只用了解码器(Decoder-Only)
Decoder Only 的架构中解码器最后得到的最后一个数学向量,就是代表了整个段落的语义。
Q: 为什么只用Decoder?
原始Transformer是为了翻译任务设计的:
编码器:理解源语言;解码器:生成目标语言
但对于文本生成任务(比如写文章、对话),我们只需要:
输入:一段文本提示;输出:续写的内容;这种情况下,不需要分开的编码器和解码器,只用解码器就够了
Decoder-Only适用于文本生成任务(比如写文章、对话),因为它只需要输入一段文本提示,就可以生成续写的内容。完整的Encoder-Decoder适用于翻译任务(比如将英文翻译成中文),因为它需要输入源语言的文本,然后输出目标语言的文本。
# Linear & Softmax
这是 Transformer 最后的输出层,负责把机器“思考”出来的抽象向量,翻译回人类的语言。
Linear (线性层)
- 角色:投影仪。
- 作用:它把 Decoder 输出的那个高维向量(比如 12288 维,包含了整个段落的深层语义),映射(投影)到词表空间(比如 50000 维,对应词表里的 50000 个词)。
- 输出:它会给词表里的每一个词打一个分(Logits)。
- 例子:模型觉得下一个词可能是什么?
- “苹果”:得分 5.2
- “香蕉”:得分 2.1
- “汽车”:得分 -3.0
Softmax
- 角色:归一化器(概率转换器)。
- 作用:把 Linear 层输出的那些乱七八糟的分数(有的正有的负),转换成概率分布。
- 它保证所有词的概率都在 0 到 1 之间。
- 它保证所有词的概率加起来正好等于 1 (100%)。
- 输出:
- “苹果”:概率 95.2%
- “香蕉”:概率 4.7%
- “汽车”:概率 0.1%
Softmax, 多分类专用,把一堆数字转成概率分布,所有输出加起来=1,适用于多分类问题的输出层,需要概率分布的时候。
最终步骤:模型通常会选择概率最高的那一个词(Greedy Search),或者根据概率随机抽样(Sampling),作为最终生成的Next Token。
- Transformer架构流程梳理

# Encoder&Decoder揭秘
Encoder & Decoder 分析。
Encoder 和 Decoder 过去都是以循环神经网络RNN为核心计算模块;后来进化为由 注意力机制 + 神经网络 组成
# 循环神经网络RNN
RNN是一种专为处理序列数据(如时间序列、文本)设计的神经网络。它的核心思想是:在处理序列的每个元素时,不仅考虑当前输入,还考虑之前所有元素的“记忆”(隐藏状态)。
网络结构:
- RNN单元有一个隐藏状态h(0),它在时间步之间传递,捕获到当前为止的序列信息;
- 在每一个时间步t,RNN接收当前输入x(t), 和上一个隐藏状态h(t-1),计算当前隐藏状态
h(t) = tanh(W * [h_{t-1}, x_t] + b); - 然后,可以根据h(t)输出预测结果(例如,下一个词的概率)。
特点:串行处理,必须按顺序一个字一个字地读,会出现长距离依赖丢失问题
例:“小明从小就爱吃苹果……(中间过了1000字)……所以他牙齿很好。” RNN 读到最后的“他”时,可能已经忘了开头的主语是“小明”。
RNN的优势(为什么曾经流行)
- 天然的序列处理者:处理变长序列很自然
- 参数共享:同一套参数处理所有时间步,模型较小
- 考虑历史:理论上可以记住整个历史
RNN的劣势
- 梯度消失/爆炸:这是RNN最严重的问题。当RNN处理长序列(如50个词以上)时,需要通过链式法则反向传播梯度来更新权重。这个梯度要穿越许多时间步,会指数级地缩小(消失)或放大(爆炸),导致网络难以学习长距离依赖,无法处理较长句子。
- 顺序处理,无法并行:RNN必须按时间步顺序处理序列,无法利用现代GPU的并行计算能力,不能并行计算,速度慢,算力利用率低。
- 长期记忆困难,信息易丢失,记忆力差:即使有LSTM和GRU等改进,但实际中仍然难以记住非常长的序列中的信息。
LSTM(长短期记忆网络)是对 RNN 的改良,通过“记忆通道 + 三个门(遗忘、输入、输出)”来控制信息的保留与遗忘,
缓解梯度消失,能记更长的上下文。
GRU 是 LSTM 的简化版,门更少(更新门、重置门),更轻更快,效果接近。
Q:什么是时间步 (Time Step)?
在处理序列数据(如文本、语音)时,时间步就是序列的顺序索引。
- 文本中:第一个词是 Time Step 1,第二个词是 Time Step 2……
- RNN 的限制:它必须在 Time Step $t$ 完成后,才能进入 Time Step $t+1$。就像看电影,必须一帧一帧按顺序看,不能直接跳到结尾。
- Transformer 的突破:它把所有 Time Step 的数据拼成一张图,一次性输入。就像看漫画书,一整页画面同时映入眼帘,一眼就能看清所有格子的关系(并行)。
# 注意力机制 (Attention)
RNN 是早期处理序列数据的主流模型,而注意力机制(尤其是自注意力)是Transformer的核心,它解决了RNN的多个关键瓶颈。
一种让模型动态聚焦于输入不同部分的机制。给定查询(Query)和一组键值对(Key-Value),注意力通过计算查询与每个键的相似度,得到权重,再对值加权求和。
核心思想:让模型在处理一个词时,把注意力放在其他跟自己相关度比较高的数据上。
注意力机制(Attention)让模型能够:
- 并行处理: 不像RNN那样必须一个一个字处理,Transformer可以同时看所有输入
- 长距离依赖: 轻松捕捉句子中相隔很远的词之间的关系
- 动态权重: 根据上下文动态调整每个词的重要性
计算步骤(以经典的点积注意力为例):
- 对于每一个查询(Query,通常为解码器的当前隐藏状态),计算它与所有键(Key,通常为编码器的所有隐藏状态)的相似度(如点乘)。
- 将这些相似度通过softmax函数归一化为权重(注意力权重)。
- 用这些权重对值(Value,通常也为编码器的隐藏状态)进行加权求和,得到上下文向量(Context Vector)。
- 将上下文向量与当前解码器的隐藏状态结合,产生输出。
相关度系数的计算:点乘 + Softmax(归一化)
注意力权重 = softmax(目标Query 与 各个源Key 的相似度)
输出 = Σ(注意力权重 × 各个源Value)
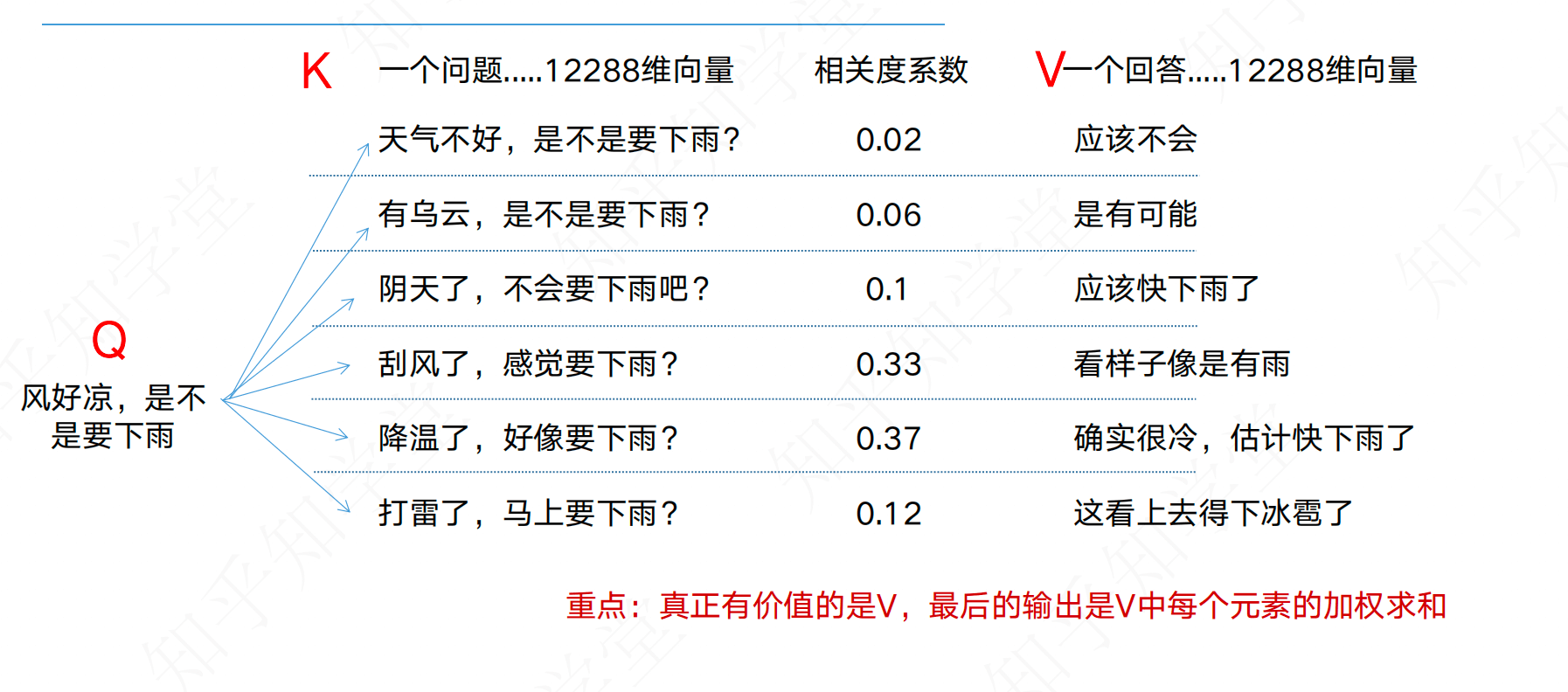
QKV的定义和计算
Q, K, V 是什么?想象你在图书馆找书:
- Query (Q) :你手里的书单(你的需求)。
- Key (K) :书脊上的标签(书的特征)。
- Value (V) :书里的正文内容(真正的知识)。 过程 :
- 你拿你的需求 (Q) 去和每一本书的标签 (K) 进行比对(计算相似度/注意力分数)。
- 如果匹配度很高(相关度系数高),你就把这本书的内容 (V) 多读一点。
- 如果匹配度很低,你就忽略它。
- 最后,你脑子里的知识就是所有书内容 (V) 的加权总和。
结果:你得到了一个融合了所有相关知识的新向量(Attention Output)。这就是为什么 Transformer 能理解“上下文”。
相关度系数矩阵的计算是很耗算力的, 如果输入是1000个Token,计算量是 1000^2。
整个计算过程没有神经网络,比较依赖Embedding向量、位置向量,也会带来一些问题
# 自注意机制(Self-Attention)
在Transformer中,注意力机制被扩展为自注意力,即序列中的每个元素都作为Query、Key和Value,计算序列内部所有元素之间的注意力。
是注意力的一种特例,查询、键、值都来自同一个输入序列。Transformer中的自注意力让每个位置都能关注序列中的所有其他位置,从而捕获长距离依赖。
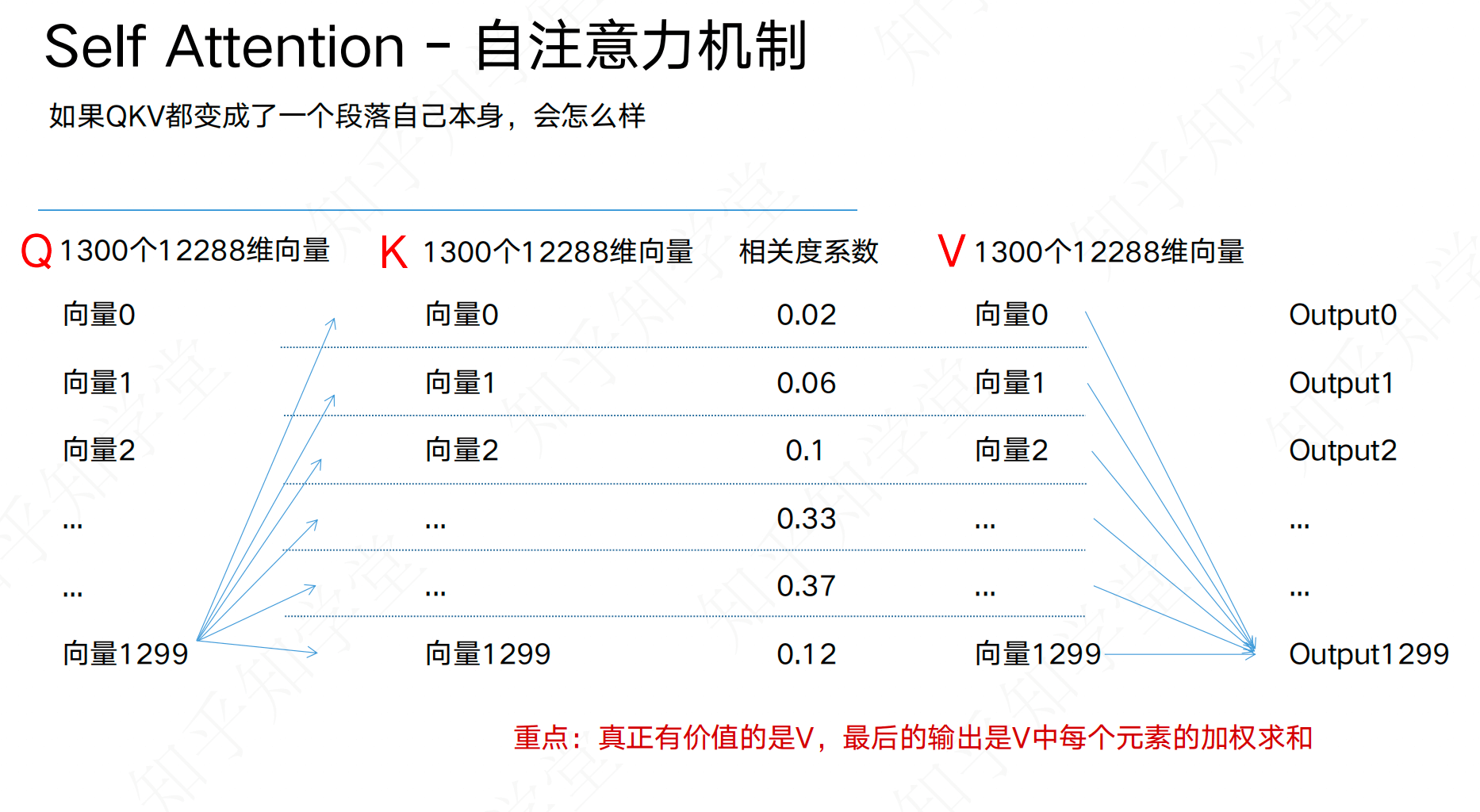
核心目标是做信息聚合。
Q: 请简述一下什么是 Self-Attention (自注意力机制)?
从三个层面来解释:
直观理解(它解决了什么?) 在处理多义词或代词时,它非常有效。比如句子
The animal didn't cross the street because **it** was too tired。 传统的模型可能不知道这个 it 指的是 animal 还是 street。但 Self-Attention 能计算出 it 和 animal 的关联度最高,从而正确理解语义。它解决了长距离依赖的问题。工作原理(QKV) 它的核心是把每个词映射成三个向量:Query (查询)、Key (键) 和 Value (值)。就像在数据库里查数据一样,拿当前词的 Query 去和句子里所有词的 Key 做点积(计算相似度),得到权重(Attention Score),然后根据这个权重去聚合所有词的 Value。
自(Self)的意思就是,Query、Key、Value 都来自同一个输入序列,是自己查自己。
技术优势 相比于 RNN/LSTM 这种串行处理,Self-Attention 最大的优势是并行计算。它不需要读完上一个字才能读下一个,而是一眼看清全句,这大大提高了训练效率,也让 Transformer 能够在大规模数据上训练成为可能。
Q:自注意力机制为什么可以实现并行计算呢?
“这主要得益于它抛弃了时间步(Time Step)的依赖,把串行计算变成了矩阵运算。
- RNN 的瓶颈(接力跑):
- RNN 计算第 2 个词必须依赖第 1 个词的结果(Hidden State)。
- 这就好比接力赛跑,下一棒必须等上一棒交接,无法同时跑。GPU 即使有几千个核,也只能看着一个核在干活,效率极低。
- Attention 的突破(大合唱):
- 在 Transformer 中,输入的一句话被打包成一个矩阵(Matrix)。
- 计算 Attention Score (Q 与 K 的相似度) 时,本质上是做矩阵乘法 ($Q \times K^T$)。
- 矩阵乘法是 GPU 的强项:GPU 可以同时计算矩阵中所有的数值,不需要任何等待。
- 形象比喻:这就好比大合唱,指挥棒一挥,所有人(所有的 Token)同时开口,谁也不用等谁。
总结:RNN 是时间维度的串行(Loop),Transformer 是空间维度的并行(Matrix Multiplication)。这就是为什么它能训练得这么快。”
缺点:对于长度为 n 的序列,自注意力的时间和空间复杂度均为 O(n2)。当 n 达到数万甚至数十万(如处理整本书、长视频、基因组序列)时,计算和内存开销会变得不可承受。
点乘,欧式距离,余弦相似度
| 指标 | 关注点 | 核心公式 | 典型应用场景 | 为什么选它? |
|---|---|---|---|---|
| 点乘 (Dot Product) | 方向 + 力度 | $A \cdot B$ | Transformer 内部 (Self-Attention) | 1. 快:GPU 做矩阵乘法最快。 2. 保留强度:向量越长代表特征越明显(权重越大),点乘能保留这种“强弱”区别。 |
| 余弦相似度 (Cosine) | 只看方向 | $\frac{A \cdot B}{|A||B|}$ | RAG (检索) / 文本匹配 | 1. 公平:不管句子长短,只看意思像不像。 2. 归一化:把大家都拉到同一起跑线,避免长文本占便宜。 |
| 欧式距离 (Euclidean) | 绝对距离 | $|A - B|$ | 聚类 (K-Means) / 推荐 | 在低维空间好用。但在高维空间(几千维)里,所有点之间的距离都会变得差不多(维数灾难),所以 LLM 很少用。 |
直观比喻:
- 点乘 (Transformer):“拔河比赛”。不仅看大家是不是往同一个方向拉(方向),还要看谁力气大(模长)。力气大的 Token 应该获得更多的关注。
- 余弦相似度 (RAG):“照镜子”。不管你是巨人还是蚂蚁,只看长得像不像。检索时我们只关心内容匹配,不关心文本长度。
- 欧式距离:“拿尺量”。直接测量两点之间的直线距离。
总结:
- 搞训练/推理 (Transformer):用点乘(追求效率和强弱表达)。
- 搞检索 (RAG):用余弦相似度(追求语义对齐和公平)。
# 稀疏注意力机制(Sparse Attention)
稀疏注意力是标准自注意力的一种改进,旨在降低计算复杂度。标准自注意力中,每个token要关注所有token,复杂度
O(n^2)。稀疏注意力通过限制每个token只关注一部分token(如局部窗口、固定的稀疏模式、基于内容选择等),将复杂度降低到O(n log n)或O(n√n)等。
稀疏注意力是对自注意力矩阵施加稀疏约束,即每个位置只关注整个序列中的一小部分位置,而不是所有位置。
稀疏注意力是应对长序列Transformer计算瓶颈的重要技术,是大模型处理长上下文的关键。
稀疏注意力仍然是一种自注意力(Q、K、V同源)。它是标准自注意力的近似变体,通过预先定义的稀疏模式或基于数据动态选择的稀疏模式,跳过大部分无关的位置计算。
常见的稀疏注意力模式
| 模式 | 描述 | 代表工作 |
|---|---|---|
| 滑动窗口 | 每个位置只关注左右各 w 个邻近位置 | Longformer、BigBird |
| 空洞滑动窗口 | 滑动窗口内按固定间隔采样,扩大感受野 | BigBird、Sparse Transformer |
| 分块/块模式 | 将序列分成块,块内全连接,块间稀疏连接 | BlockSparse、Sparse Transformer |
| 全局记忆 | 插入少量全局token,它们关注所有位置,同时所有位置也关注这些全局token | Longformer、BigBird、ETC |
| 随机稀疏 | 随机采样一部分位置进行关注,降低方差 | BigBird |
| 基于内容/聚类 | 根据向量相似度将token分组,只在组内或组间稀疏交互 | Reformer(LSH)、Routing Transformer |
| 查询无关稀疏 | 用固定的、与输入无关的稀疏模板 | Sparse Transformer(固定步长) |
稀疏模式会损失一部分全局信息,因此需要精心设计模式并配合位置编码、全局token等补偿手段。
# 多头注意力机制(Multi-Head Attention)
单头注意力有个问题:它只能学习一种关系模式。但语言中的关系是多样的,多头注意力机制是自注意力机制的一种扩展,它允许模型同时关注输入序列中的不同位置。
并行运行多个自注意力层,让模型在不同的“表示子空间”中学习不同的关系模式。
每个头都有自己的 Q, K, V 矩阵,每个头的计算结果会被拼接起来,最后通过一个线性层得到最终的输出。
多头注意力机制的优势在于,它可以并行计算,从而提高模型的效率。
Q: 那你能详细说说什么是 Multi-Head Attention (多头注意力) 吗?
多头注意力机制,本质上就是多视角。
如果只用一组 Q、K、V(单头),模型可能只能捕捉到一种类型的关联,比如语法结构(主谓宾关系)。但语言的含义是很丰富的,可能同时包含指代关系、情感倾向、上下文逻辑等。
Multi-Head 的做法是:
- 分工:将输入的Q、K、V向量投影到多个更低维的子空间(比如8个或16个),在每个子空间上独立运行自注意力计算,将所有头的输出拼接起来,再通过一个线性层融合。
- 形象理解:就像看一篇文章,Head-1 专门负责看语法,Head-2 专门负责看指代,Head-3 专门看情感...
- 拼接 (Concat):最后把这 8 个头算出来的结果拼接在一起,经过一次线性变换(Linear)融合。
这样做的好处是:
- 表征能力更强:捕捉不同类型的关系。
- 更稳定:类似于集成学习,降低模型对单个关系模式的依赖。
- 可解释性:有时可以可视化不同头关注的不同语言现象。
# Masked Self-Attention (带掩码的自注意力机制)
核心作用是 “防作弊” 。
在训练生成式 AI(如 GPT)时,我们是让它 根据上文猜下文 (Predict Next Token)。
- 如果不加 Mask,Attention 机制会让模型一眼看到整句话(包括后面的答案)。
- Mask 的作用 :强行把“未来”的词遮住,让模型在猜第
t个词时,只能看到第1 到 t-1个词。
如何实现? 在计算 Attention Score 时,把代表“未来”的位置填上一个负无穷大的数(Mask)。经过 Softmax 后,这些位置的概率就变成了 0。
例子: 输入:“我 爱 中国”
- 预测“爱”时:只能看见“我”。
- 预测“中国”时:只能看见“我”、“爱”。
- 如果不加 Mask:预测“爱”的时候直接看见了后面的“中国”,那模型就学会了“抄答案”,而不是“学逻辑”。
# 前馈神经网络 (FFN)
在 Transformer 的每一层中,Attention 之后紧接着就是 FFN(Feed-Forward Network, 前馈神经网络)。如果说 Self-Attention 负责收集上下文信息,那么 FFN 就负责处理收集到的信息。
- 结构 :非常简单,通常就是两层全连接层 (Linear) 加上一个激活函数 (ReLU/GELU)。 Linear -> Activation -> Linear 。
- 作用 :它对每个 Token 独立 进行非线性变换。
- Attention 层是把大家的信息混在一起(聚合)。
- FFN 层是把每个 Token 自己的信息再加工一下(提炼特征)。
- 比喻 :
- Attention:小组讨论,大家交换意见。
- FFN:个人思考,把听到的意见消化成自己的理解。
前馈神经网络的训练过程可以分为以下三步:
- 前向计算每一层的状态和激活值,直到最后一层
- 反向计算每一层的参数的偏导数
- 更新参数
# Add (残差连接) 和 Norm (层归一化)
Add (残差连接) 和 Norm (层归一化) 是 Transformer 中两个不起眼但至关重要的“稳定器”,没有它们,深层网络根本训练不起来。
Add (Residual Connection, 残差连接):防止“梯度消失”。 在深层网络中,信息传着传着容易丢(梯度消失);残差链接就是告诉模型:不管你这层学得怎么样,至少先把上一层的知识保留下来。这为信息传递修了一条高速公路。
Norm (Layer Normalization, 层归一化):防止“梯度爆炸/数值不稳定”。网络层数多了,数据数值会忽大忽小,导致模型忽冷忽热,很难收敛;把每一层输出的数据,强行调整成均值为 0、方差为 1 的标准正态分布。
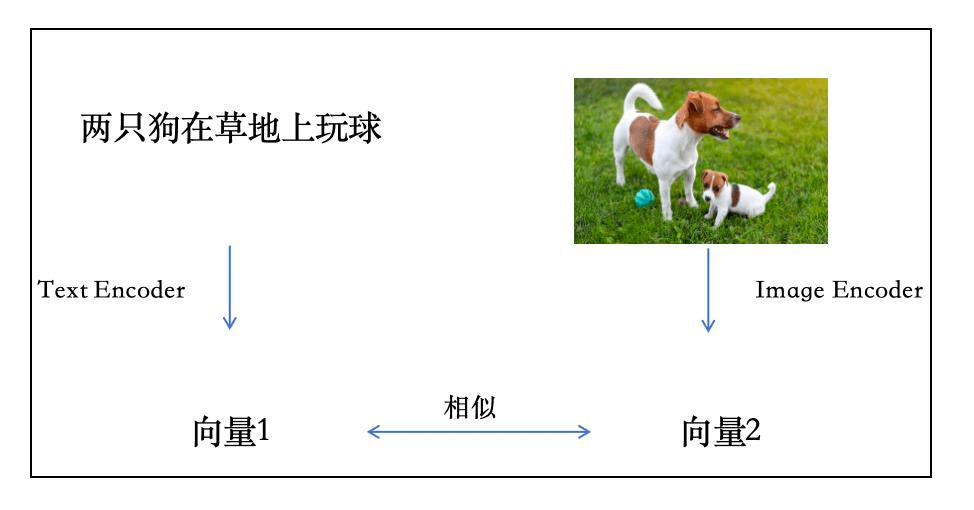
# 多模态
多模态 (Multimodal) 指的是 AI 能够同时理解和处理 多种不同类型的数据 (如文本、图片、声音、视频)。
- 单模态 (Unimodal) :比如早期的 ChatGPT 只能读写文字,它是“瞎子”和“聋子”。
- 多模态 (Multimodal) :比如 GPT-4o,它能 看图 (视觉)、 听录音 (听觉)、 读文章 (文本),并理解它们之间的关系。
如何打通:一个模型,能同时看懂语言和视觉,
进阶能力:能输出文字,也能输出图片、视频
好处:视觉转译、融合推理、视觉编辑
# 视觉识别vs视觉推理
传统视觉识别模型 vs 多模态模型
传统视觉识别模型:Yolo、UNet
- Yolo:目标物体的识别
- UNet:具体区域的分割
- 优势:模型小、部署和使用成本低、识别精度高
- 劣势:需要单独标注数据、训练模型
多模态模型:Gemini、GPT,Qwen VL、豆包 Seed
- 优势:无需标注、无需训练、直接使用、有推理能力
- 劣势:部署和使用成本较高,精度中等
# 视觉生成
模型能力不足时的综合方案
模型能力不足:只是写提示词给模型,生成的视频无法满足需求
- 海报生成
- 漫剧视频
- 电商视频
传统图像识别模型:输入 =》数据获取 =》 预处理 =》 特征提取 =》决策分类 =》 输出
- 数据获取:通过图像输入设备实现。
- 预处理:提高图像质量,包括滤波、平滑、增强、复原、提取边缘、图像分割等方法
- 特征提取和选择:将预处理后的图像转化为若干特征:常见特征有幅度特征,统计特征,几何特征,变换系数特征等
传统视觉检测:
- 依靠特征工程,制定一系列的规则 =>确定检测目标是否符合标准
- 代表软件:Halcon, Visionpro, OpenCV
- 缺点:检测物体发生了变动,所有的规则和算法都要重新设计,即使是同样的产品,不同的批次也会带来变化,很难有一种规则适用所有的情况
深度学习视觉检测:
- 采用深度神经网络,传统的机器视觉检测中,有许多不易被识别的变量,比如:照明、颜色变化、曲面、或视野
- CNN是目前深度学习最广泛的模型之一:yolo, Faster RCNN
- 缺点:数据量要求大,工业数据收集成本高 => 采用数据增强,无监督学习,学术界在研究的,自动数据标注等
# 卷积神经网络 (CNN)
卷积神经网络 (CNN, Convolutional Neural Network) ,一种专门处理网格状数据(如图像)的神经网络架构。是多层感知机(MLP)的一个变种模型,它是从生物学概念中演化而来的。
核心是卷积层,通过卷积核(滤波器)在输入上滑动提取局部特征,具有参数共享和平移不变性等优点。
CNN学习可以帮我们进行特征提取,比如我们想要区分人脸和狗头,那么通过CNN学习,背景部位的激活度基本很少;CNN layer越多,学习到的特征越高阶。
什么是 CNN?
- 核心能力 :擅长处理 网格状数据 (比如图片)。
- 工作原理 : “拿放大镜扫描” 。用一个小窗口(卷积核)在图片上滑来滑去,提取局部特征(如边缘、纹理)。
- 特点 : 局部性 (只看眼前的一小块)、 平移不变性 (猫在左边还是右边都能认出来)。
形象比喻:拿放大镜扫描
- 想象你在看一张《清明上河图》。
- 你手里拿个放大镜(卷积核/Filter),从图的左上角开始,一小块一小块地往右下角移动(滑动窗口)。
- 每到一个位置,你就记录下这一小块画了什么(特征提取)。
- 最后,你把所有记录下来的局部特征拼在一起,就理解了整幅画。
CNN 的本质:多层拼图游戏
- 先用S细胞(卷积) 找到无数个小碎片(横线、竖线、圆弧)。
- 再用C细胞(池化) 忽略掉无关紧要的位置抖动。
- 最后层层叠加,把线条拼成眼睛,把眼睛拼成脸,把脸拼成完整的人
LLM 训练中会用到吗?
- 纯文本 LLM (如 Llama 3):基本不用。处理文本序列是 Transformer 的强项,CNN 处理长距离依赖(比如文章开头和结尾的关系)能力较弱。
- 多模态 LLM (如 GPT-4o):大用特用。
- 场景:视觉编码器 (Visual Encoder)。
- 流程:当你要发一张图给 GPT-4 时,模型内部会先用 CNN (或 ViT) 像放大镜一样扫描这张图,提取出“有只猫”、“在草地上”等特征向量,然后再把这些向量喂给 Transformer 去理解和对话。
YOLO
CNN (卷积神经网络) 是 技术组件。它的功能只有一个:看图。它负责从图片里提取特征(比如一只猫,CNN 负责找出横线、竖线、眼睛、耳朵)。
YOLO (You Only Look Once) 是 解决方案/架构。它是一个设计精妙的算法框架。把这一堆 CNN 按照特定的顺序组装起来,不仅要看懂图,还要算出物体在哪个位置(坐标)。=> CNN 是砖块,YOLO 是用砖块盖起来的摩天大楼。
YOLO广泛应用于各种需要目标检测的场景:
- 自动驾驶:检测道路上的车辆、行人、交通标志等,为自动驾驶系统提供决策依据。
- 安防监控:在视频监控中实时检测可疑人物或物体,提高安防效率。
- 机器人视觉:帮助机器人识别和定位周围的物体,实现自主导航和操作。
- 智能交通:用于交通流量监测、违章检测等,提高交通管理的智能化水平。
# 扩散模型 (Diffusion Model)
什么是 Diffusion? 它是目前 AI 绘画(如 Midjourney, Stable Diffusion, DALL-E)和 AI 视频(如 Sora)背后的核心技术。
核心原理:破坏与重建 (加噪与去噪)
形象比喻:修复文物
- 前向过程(加噪):把一张清晰的照片(比如蒙娜丽莎),慢慢撒上沙子(高斯噪声),直到最后变成一片完全看不清的随机噪点。
- 反向过程(去噪):让 AI 学习逆向操作。给它看那堆沙子,让它猜原来长什么样,一步步把沙子擦掉,最后变回清晰的画。
- 神奇之处:只要你告诉它“这是一只猫”,它就能从一堆随机噪点里“擦”出一只猫来。
它在 LLM 训练中的角色
- 纯文本 LLM:一般不用。文本生成通常用 Transformer 的“自回归”(接龙)模式。
- 多模态 LLM:它是画师。
- 当你对 ChatGPT 说“画一只猫”时,LLM 负责理解你的指令(Prompt),然后指挥背后的 Diffusion 模型去生成图片。
| 模型类型 | 核心逻辑 | 典型代表 | 擅长领域 |
|---|---|---|---|
| Autoregressive (自回归) | 接龙。根据上文猜下文。 | GPT, Llama | 文本生成、代码编写 |
| Diffusion (扩散) | 去噪。从混沌中恢复秩序。 | Stable Diffusion, Sora | 图片生成、视频生成 |
# GPT训练阶段
- GPT(OpenAI的大模型)
- Pretrain,预训练
- SFT(Supervised Fine-Tuning),有监督微调训练
- Reward Model,奖励模型
- PPO(Proximal Policy Optimization),近端策略优化
# Pretrain
预训练。需要大量的数据集,耗时长,耗算力
训练数据:token(M:百万,B:十亿,T:万亿)
文本补全:预训练学习数据集,计算当前文字后面出现下一个文字的概率,推理计算,不停输出
段落联合概率:让一个模型,能一字不落的生成整个段落的概率
预训练阶段就是不断提高模型的平均段落联合概率。
LLM 在预训练(Pretrain)阶段提高段落联合概率的核心机制就是 Next Token Prediction(下一个词预测) 。虽然“段落联合概率”听起来很高深,但实际上模型并不是一次性算出整个段落的概率,而是通过 链式法则(Chain Rule) ,把大问题拆解成无数个小问题: “基于前面的字,猜下一个字是什么?”
训练过程
- 给模型看海量的文本(比如整个互联网的网页)。
- 遮住下一个字,让模型猜。
- 猜对了(概率高),奖励;猜错了(概率低),惩罚(调整参数)。
- 重复万亿次(Trillions of tokens)。
当模型能精准预测每一个“下一个字”时,它自然就能生成流畅、符合逻辑的整个段落,也就是提高了“段落联合概率”。
预训练后,会得到一个非常熟悉人类语言的模型,阅读过大量的人类文献资料,语言能力与人类近似,只要给出一些初始的文字,猜下一个字的能力也与人类近似。
但还存在核心问题:预训练模型(Pretrain)说起话来非常像“接话茬”,并不是在“做任务”
# SFT(Supervised Fine-Tuning)
有监督的微调训练。
- 使用有标签的数据进行训练,学习过程叫做有监督学习
- 使用无标签的数据进行训练,学习过程叫做无监督学习
Pretrain阶段的处理方式,就叫做自监督
Pretrain + SFT 两个阶段组合起来就叫做半监督(不缺数据,但缺标签)
如果未来你希望做什么类型的任务,就用什么样的数据去做指令微调(Instruction Tuning)
对话任务、分类任务、判断任务、推理任务、代码生成任务
Instruction Tuning 是 Fine Tuning 的一种,基本都是使用有监督(Supervised)学习,也就是 SFT(Supervised Fine-Tuning)。
经过SFT,我们得到了一个,会做各类任务的模型,尤其是对话任务。
大模型的主要能力其实就是续写。
但还存在核心问题:会做任务,和能优秀的做任务,还是有很大差距
# Reward Model
奖励模型
强化学习:从游戏中引入大模型
- 准备一系列Prompt(问题),让模型给每个问题 生成多个回答;
- 然后找标注工程师对每个回答进行打分,排序;
- 然后再用这些标注数据训练出奖励模型;目标是大模型任意给一组问题-答案,Reward Model 就可以给出一个打分
Preference Data,偏好数据,人类标注的,模型输出的回答,人工判断的好与坏的一组数据。
# PPO(Proximal Policy Optimization)
近端策略优化(Proximal Policy Optimization, PPO)是一种强化学习算法,旨在让智能体通过与环境的交互学习最优策略。
- 它允许模型根据反馈(Reward)去调整自己的参数(Policy),但它强制要求 “每次只能改一点点”(Proximal/近端)。
- 为什么 :因为大模型很脆弱,如果因为一个错误的反馈改动太大,模型可能瞬间就“傻了”(崩溃)。PPO 保证了改进的稳定性。
当模型收到奖励(Reward)需要改进时,PPO 会限制模型“步子不要迈得太大”。
- 它允许模型更新参数来获取更高的奖励。
- 但它强制要求新的策略(Policy)不能偏离旧策略太远(Proximal)。
# ChatGPT训练流程
这是 OpenAI 定义的经典 RLHF 三部曲,是后续所有大模型对齐的基石。
RLHF,Reinforcement Learning from Human Feedback,基于人类反馈的强化学习,OpenAI训练大模型的方法,即:预训练 =》 SFT =》奖励模型 =》 强化学习(PPO) =》奖励模型 =》 。。。 =》
第一步:SFT (Supervised Fine-Tuning)
- 做法:人类标注员编写大量的高质量“问题-答案”对。
- 目的:让 GPT-3 这样的基座模型学会对话的格式,从“续写”模式切换到“问答”模式。
- 产出:SFT 模型。
第二步:Reward Modeling (奖励模型训练)
- 做法:
- 用 SFT 模型对同一个问题生成 4-9 个不同的回答。
- 人类标注员对这些回答进行排序(A 比 B 好,B 比 C 好...)。
- 用这些排序数据训练一个 Reward Model。
- 目的:得到一个能模仿人类喜好打分的“裁判模型”。
- 产出:Reward Model (RM)。
第三步:PPO (Reinforcement Learning)
- 做法:
- 让 SFT 模型生成回答。
- RM 给回答打分。
- PPO 算法根据分数更新 SFT 模型的参数。
- 目的:利用“裁判”的反馈,大规模优化模型,让它生成的回答尽可能拿高分。
- 产出:最终的 ChatGPT 模型 (RLHF 模型)。
# Llama训练阶段
- Llama(Meta的大模型)
- Pretrain,预训练
- Reward Model,奖励模型
- Rejection Sampling,拒绝采样
- SFT(Supervised Fine-Tuning),有监督微调训练
- DPO(Direct Preference Optimization),直接偏好优化
# DPO(Direct Preference Optimization)
直接偏好优化,是一种强化学习算法,旨在通过直接优化奖励模型来学习最优策略。
DPO 发现了一个数学上的捷径:与其训练一个裁判来打分,不如直接把考题的答案告诉学生。
- 它不再需要训练一个独立的 Reward Model。
- 它直接利用
(Prompt, Good_Answer, Bad_Answer)这样的数据对。 - 它在数学上推导出一个 Loss 函数,直接让模型增加生成 Good_Answer 的概率,同时降低生成 Bad_Answer 的概率。
- 作用:大大简化了流程,省去了维护 Reward Model 的显存开销,训练更稳定。
PPO :核心是“稳”(Proximal),小步稳定迭代。
DPO :核心是“直”(Direct),不绕弯路找裁判,直接对着答案练。
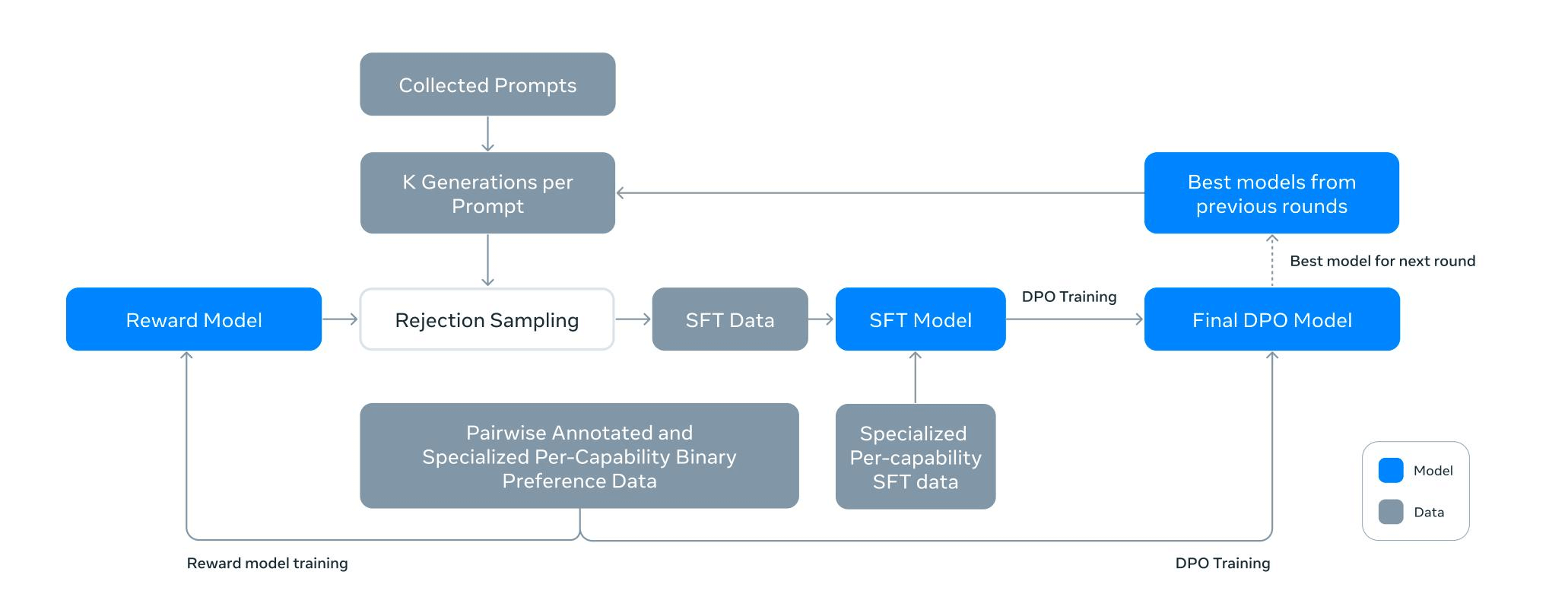
# Llama 3 训练流程
- 人类标注偏好数据 =》训练奖励模型,产出一个可以打分的教练员;
- 初始 SFT:先用高质量的指令数据微调,得到一个基础版模型。
- 生成与打分 (Rejection Sampling):
- 用当前最好的模型对每个 Prompt 生成多个回答 (N个)。
- 用 Reward Model (奖励模型) 给这些回答打分,选出分数最高的那个作为“标准答案”。
- 这就构建了新的、更高质量的 SFT 数据集。
- SFT 训练:用上面生成的高质量数据,重新进行 SFT 微调。
- DPO 训练:用偏好数据对模型进行 DPO 优化,进一步对齐人类喜好。
- 迭代:重复步骤 3-5(通常进行多轮)。
核心逻辑:
- Reward Model 是裁判。
- DPO 让模型学会裁判的喜好。
- Rejection Sampling 是利用模型自己生成的数据来“自我蒸馏”,自己教自己。
# 深度学习框架
深度学习框架:Tensorflow, Keras, PyTorch, Paddle(百度自研AI框架飞桨)
- Tensorflow, google出品的深度学习框架;2.0, 2019年发布,相比于1.0更加简洁
- Pytorch,Facebook开发,Python + Torch
| 对比维度 | TensorFlow | PyTorch |
|---|---|---|
| 开发风格 | 早期静态图,2.0后支持动态图(Eager模式) | 原生动态图(即时执行),调试方便 |
| 生态系统 | 工业部署工具完善(TF Serving, Lite等) | 学术研究主流(Hugging Face等) |
| API设计 | API复杂但功能全,Keras高层封装 | Pythonic风格,代码简洁直观 |
| 硬件支持 | GPU/TPU/移动端优化成熟 | GPU/TPU支持良好,移动端支持较弱 |
| 适用场景 | 生产环境、大规模部署 | 快速实验、学术研究 |
| 社区趋势 | 工业界应用广泛 | 学术界占比高,近年工业界渗透增加 |
两者的核心用途高度重合,都是支持深度学习模型从研究到生产的全流程,主要包括:
- 模型构建:提供模块化的神经网络层(卷积、循环、注意力等)、损失函数、优化器等组件。
- 自动微分:自动计算梯度,支撑反向传播。
- 模型训练:支持GPU/TPU加速、分布式训练、混合精度训练等。
- 模型部署:将训练好的模型导出,运行在云端服务器、移动端、嵌入式设备或网页浏览器上。
- 研究实验:快速迭代新算法、网络结构。
- 工业应用:计算机视觉、自然语言处理、推荐系统、语音识别、强化学习等几乎所有AI落地场景。
# NumPy
NumPy 是 Python 中最基础的数值计算库,全称 Numerical Python,提供多维数组对象和大量数学函数。
NumPy可以手动实现前向传播、反向传播等,但缺乏自动微分和GPU加速。使用 NumPy 搭建神经网络可以帮助理解神经网络的工作原理,但在实际应用中,建议使用专业的深度学习框架(如 TensorFlow、PyTorch),它们提供了更高级的抽象和优化。
NumPy代码繁琐、容易出错、只能用CPU,不支持 GPU 加速,难以扩展到大模型。
# TensorFlow
TensorFlow的计算图(Graph)是一个由节点(操作)和边(张量)组成的数据流图,描述计算的依赖关系。
优点:
- 高效执行:图优化(如算子融合)可提升性能。
- 跨平台支持:可导出到移动端、嵌入式设备等。
- 计算图可加速计算,图模式下运算在C++层执行,避免Python循环的慢速交互。
- 能并行化优化:自动调度无依赖的节点并行计算(如GPU/多核CPU)。
张量(Tensor) 是 TensorFlow 中的核心数据结构,可以理解为多维数组。
- 标量(0维):单个数值(如 3.0)。
- 向量(1维):一维数组(如 [1, 2, 3])。
- 矩阵(2维):二维表格(如 [[1, 2], [3, 4]])。
- 高维张量:如 RGB 图片(3维:[高度, 宽度, 通道])。
张量存储数据,并在计算图中流动,支持自动求导和 GPU 加速。
TensorFlow 2.x
在 TensorFlow 2.x 中,传统的 计算图(Graph)+ 会话(Session) 模式被大幅简化,但仍保留核心优化能力,主要通过 tf.function 和 即时执行(Eager Execution) 结合使用。
tf.function:自动构建计算图。将普通 Python 函数转换为 TensorFlow 计算图,提升执行效率(如减少 Python 调用开销)- 加速训练/推理:适合循环、矩阵运算等密集计算。
- 跨平台部署:可导出为 SavedModel 供 TensorFlow Serving 使用。
即时执行(Eager Execution):Tensorflow2.0默认模式,一种交互式编程模式,让代码像普通 Python 程序一样逐行运行(类似NumPy),无需先构建计算图,便于调试。
分布式训练的基本方式
- 数据并行:将训练数据拆分到多个设备(如GPU/CPU),每个设备计算梯度后同步更新模型(主流方案)。
- 实现工具:tf.distribute.MirroredStrategy(单机多卡)、MultiWorkerMirroredStrategy(多机多卡)。
- 参数服务器(Parameter Server):部分设备存储模型参数,其余设备计算梯度(适合超大模型)。
Q: 如何进行模型并行?
将模型的不同层拆分到不同设备(如GPU)上运行(适合显存不足的超大模型)。可以手动用 tf.device 指定设备:
with tf.device('/GPU:0'): # 第一个GPU
layer1 = Dense(128)(input)
with tf.device('/GPU:1'): # 第二个GPU
layer2 = Dense(10)(layer1)
适用场景:数据并行:常规模型(如CNN、BERT)。模型并行:显存不足的超大模型(如DeepSeek-R1)。
只需在有多块GPU的环境下运行,即可自动并行训练。如果只有一块GPU或CPU,也能正常运行,只是不会并行。
TensorFlow Serving:TensorFlow 官方的生产级模型部署系统,专为机器学习模型的高性能推理服务设计。将训练好的模型(SavedModel)封装为可调用的API(REST/gRPC)。
- 模型导出:训练后保存为SavedModel格式(包含计算图和权重)
tf.saved_model.save(model, "/model/1") # 版本号作为子目录
- 启动服务:通过Docker或直接运行
docker run -p 8501:8501 --name=tfserving \
-v "/model:/models" -e MODEL_NAME=my_model \
tensorflow/serving
- 客户端调用:通过HTTP/REST请求获取预测结果
# PyTorch
PyTorch是一个深度学习框架,就像你盖房子用的工具箱,提供了张量计算、自动求导、GPU加速等基础功能,你可以用它来实现各种神经网络模型。
Transformer是一种神经网络架构,是一种具体的模型设计方案,可以用PyTorch这套工具,按照Transformer的设计图,把模型搭建出来。
PyTorch = NumPy + GPU,NumPy 很好用,但只能用 CPU,在大数据面前太慢。
PyTorch解法:Tensors(张量)用法和 NumPy 几乎一样(ones, zeros, add),唯一的区别是它可以被搬运到显卡(GPU)上跑,速度快几十倍。
PyTorch提供了丰富的张量操作(如加减乘除、矩阵运算),适合高效处理数值计算。
Torch功能函数
- 数学太难:卷积、反向传播的导数公式很难推导,PyTorch 帮我们内置好了。
- 性能优化:Python 写循环很慢,PyTorch 这些内置函数底层是用 C++ 和 CUDA(显卡语言)写的,速度快几百倍。
自动求导机 (Autograd)
- 痛点:神经网络需要通过“反向传播”更新参数,也就是求导数(梯度),手算微积分太难了。
- PyTorch解法:你只管写前向计算公式(如 y = wx + b),PyTorch 会记录你的操作。调用
.backward(),它自动就把所有导数算好了
动态图 (Dynamic Graph)
- 痛点:TF 1.x 像是在写“C++代码”,写完要编译才能跑,报错看不懂。
- PyTorch解法:与静态图框架(如TensorFlow 1.x)不同,PyTorch的计算图是动态的,每次前向传播都会实时构建新图。这使得调试更直观(可逐行执行),并支持灵活的网络结构(如循环或条件分支)。
PyTorch的分布式训练
DataParallel(单机多GPU):最简单的多GPU训练方式,只需用DataParallel包装模型,数据会自动拆分到不同GPUDistributedDataParallel(DDP,多机多GPU):更高效的分布式训练方案,每个GPU独立计算梯度,再同步聚合
PyTorch Lightning封装了分布式训练的复杂细节,只需设置accelerator="gpu"和devices=N即可自动启用多GPU
总结
- 张量计算与自动微分:核心数据结构是 Tensor,支持 GPU 加速和自动求导(autograd),适合动态构建和调试模型。
- 动态计算图:计算图在运行时动态生成,比静态图更直观,便于调试和实现复杂模型(如 RNN、GAN)。
- 丰富的模块化设计:torch.nn 提供预定义层(如卷积、LSTM),torch.optim 包含优化器(如 SGD、Adam),可快速搭建神经网络。
- 分布式训练支持:支持 DataParallel(单机多卡)和 DistributedDataParallel(多机多卡),结合 PyTorch Lightning 可进一步简化流程。
# LLM训练梳理
# 大模型训练关系脉络梳理
机器学习 (Machine Learning) # 机器学习是实现AI的一种方法,让计算机从数据中学习规律,而不是显式编程
├── 深度学习 (Deep Learning) # 深度学习是机器学习的一个子集,基于多层神经网络
│ ├── 神经网络 (Neural Network) # 神经网络是深度学习的核心模型,受人脑启发的计算模型,由相互连接的神经元(节点)组成。
│ │ ├── 神经元 # 神经元是神经网络的基本计算单元,模拟生物神经元,包含加权求和、激活函数
│ │ ├── 激活函数 # 激活函数引入非线性,使网络能学习复杂模式(如ReLU, sigmoid)
│ │ ├── 架构:CNN, RNN, Transformer等 # 不同的神经网络架构,适用于不同类型的任务(如图像分类、序列建模等)
│ │ │ │ ├── Transformer 架构 # 一种基于自注意力机制的神经网络架构,特别适合处理序列数据,如文本。
│ │ │ ├── 自注意力机制 (Self-Attention) # 允许模型在处理每个词时考虑输入序列中的所有词,通过计算每个词与其他词的注意力分数来捕捉上下文信息。
│ │ │ │ ├── 线性变换 (Linear) # 在自注意力中,输入通过线性变换(矩阵乘法)生成查询(Q)、键(K)和值(V)向量。
│ │ │ │ ├── 相似度系数
│ │ │ │ ├── Softmax # 将注意力分数转换为概率分布
│ │ │ │ └── 多头注意力 (Multi-Head Attention) # 多个自注意力并行
│ │ │ ├── 前馈神经网络 (Feed-Forward Network)
│ │ │ │ ├── 线性变换
│ │ │ │ └── 非线性变换 (如ReLU、GELU)
│ │ │ ├── 残差连接 (Residual Connection) # 有助于缓解深度网络中的梯度消失问题,使得网络可以更深。
│ │ │ └── 层归一化 (Layer Normalization) # 对每一层的输出进行归一化,使得训练过程更加稳定。
│ │ │ ├── CNN # 卷曲神经网络,擅长处理网格数据如图像
│ │ │ └── RNN # 循环神经网络,擅长序列数据如文本
│ ├── 模型 # 模型 = 神经网络 + 训练好的参数;训练好的神经网络参数组合,可进行预测
│ └── 深度学习框架框架 # PyTorch, TensorFlow(用于实现以上模型)
└── 强化学习 (Reinforcement Learning) # 机器学习的一个分支,关注如何通过与环境交互来学习策略,以最大化累积奖励。可与DL结合(深度强化学习)
├── 奖励模型 (Reward Model) # 用于训练一个可以给出奖励信号的模型
├── PPO (Proximal Policy Optimization) # 一种强化学习算法,用于微调模型
└── DPO (Direct Preference Optimization) # 另一种直接利用偏好的强化学习算法
大语言模型(LLM) = Transformer架构 + 海量文本预训练 + 大规模参数
# 大模型训练三阶段流程及概念对应
大模型使用了Transformer架构训练过程是这样的:
- 准备数据:收集海量文本(比如整个互联网的文章)
- 搭建架构:按照Transformer设计搭建神经网络
- 开始训练:让模型不断学习,调整参数
- 得到大模型:训练好后就能用了
# 训练流程:
预训练 (Pretrain) → 有监督微调 (SFT) → 奖励模型训练 (Reward Model) → 强化学习优化(PPO或DPO)
第一阶段:预训练 (Pretraining) - "学语言"
├── 目标:获得语言理解和生成的基础能力
├── 方法:无监督学习,预测下一个词
├── 关键概念:
│ ├── Transformer架构(骨架)
│ ├── 自注意力机制(理解上下文)
│ ├── 前馈神经网络(特征变换)
│ ├── 残差连接(避免梯度消失)
│ └── 层归一化(稳定训练)
└── 数学基础:
├── 线性变换(所有矩阵乘法)
├── Softmax(输出概率分布)
└── 非线性变换(激活函数)
第二阶段:有监督微调 (SFT) - "学对话"
├── 目标:学会遵循指令和对话格式
├── 方法:监督学习,最小化交叉熵损失
├── 使用相同架构,只调整权重
└── 关键点:防止灾难性遗忘(catastrophic forgetting)
第三阶段:人类偏好对齐 - "学品味"
├── 目标:生成更符合人类偏好的回答
├── 两种主要方法:
│ ├── 方法A:RLHF(基于强化学习)
│ │ ├── 步骤1:训练奖励模型(RM)
│ │ │ └── 学习区分回答好坏
│ │ └── 步骤2:使用PPO优化
│ │ ├── 强化学习框架
│ │ ├── 策略:语言模型
│ │ ├── 奖励:RM评分 + KL惩罚
│ │ └── 优化:PPO算法
│ └── 方法B:DPO(直接偏好优化)
│ ├── 直接优化偏好,无需奖励模型
│ ├── 将偏好学习转化为分类问题
│ └── 更稳定,计算成本更低
└── 核心思想:让模型理解"什么更好",而不仅仅是"什么正确"
# 总结
- Transformer架构是一种基于自注意力机制的神经网络架构,用这个架构训练出来的成品就是大模型(LLM),比如
GPT-3, GPT-4, BERT, ...
# 备注
# 过拟合 (Overfitting)
定义:模型在训练数据上表现极好(考满分),但在新数据(测试集)上表现很差。
通俗比喻:“死记硬背的书呆子”。
- 想象一个学生,他把数学课本上的所有例题连同答案都背下来了。
- 平时测验(训练集):因为全是书上的原题,他能考 100 分。
- 期末考试(测试集):老师把题目里的数字从 3 改成了 5,他就彻底不会了,因为他只记住了“答案是3”,而没有学会“怎么算”。
为什么会这样?
- 模型太复杂(参数太多),而数据太少。
- 模型把数据中的噪声(比如错别字、无关细节)也当成规律学进去了。
- 它太过于关注课本里的每一个细节(甚至包括印刷错误/噪声),而没有学到通用的规律。
怎么解决?
- 增加数据:多做题,见多识广。
- 正则化 (Regularization):强行限制模型的复杂度。
- Dropout (随机失活):训练时随机让一部分神经元“休息”(不工作)。这就像强迫学生在复习时不能看全书,只能看一部分,逼迫他学会从残缺的信息中总结规律,而不是死记硬背。
# 特征提取
定义:从原始数据(如像素、文字、声音)中,提炼出最能代表其本质属性的关键信息。
原始数据: 一张图片(比如256×256像素,3个颜色通道) 最终目标: 判断是猫还是狗
把"原始像素"转化成"可以用来分类的有用信息"的过程,就叫特征抽取。
在 AI 中的作用:
- 对于图片:神经网络提取出“边缘”、“纹理”、“眼睛形状”等特征,从而认出这是“猫”。
- 对于文本:Transformer 提取出“主谓关系”、“情感倾向”、“指代对象”等特征,从而理解这句话的意思。
传统方法的困境:
原始像素 → 手工设计的特征(边缘、纹理、颜色等)→ 分类器
↑ 这一步需要专家经验,很难
深度学习的突破:
原始数据 → 神经网络(自动学习特征)→ 输出结果
↑ 这就是特征抽取器!
核心逻辑:数据降维。把复杂的原始数据,简化成几个关键的数值,既保留了核心信息,又去掉了无用的干扰。
# BERT和GPT有什么区别
BERT和GPT都是基于Transformer架构的预训练语言模型,它们在自然语言处理领域都取得了巨大成功,但设计思想和应用方向却截然不同。
- 核心架构不同:Transformer模型由编码器(Encoder)和解码器(Decoder)两部分组成。
- BERT 使用的是 Transformer的编码器部分。编码器的特点是能够同时看到输入序列中的所有词(双向注意力),因此可以捕捉到每个词完整的上下文信息。
- GPT 使用的是 Transformer的解码器部分。解码器在预测时只能看到当前词之前的词(单向注意力),不能看到后面的词,这符合“根据已知内容预测未来”的逻辑。
- 训练目标不同
- BERT 采用掩码语言建模(Masked Language Model, MLM)。在训练时,它会随机掩盖掉输入文本中的一些词,然后让模型根据被掩盖词的左右两侧上下文来预测被掩盖的词是什么。这就像做完形填空,迫使模型充分理解上下文。
- GPT 采用自回归语言建模(Autoregressive Language Modeling)。训练时,模型逐个词地阅读文本,并预测下一个最可能出现的词。它只能根据已出现的上文来推理下文,这和人类写作或说话的方式一致。
- 应用场景不同
- BERT 擅长“理解类”任务:文本分类(如情感分析、新闻分类)、命名实体识别(如识别人名、地名)、机器阅读理解(给定文章回答问题)、句子关系判断(如自然语言推理);由于BERT能充分理解上下文,它在需要深层语义理解的场景中表现优异。
- GPT 擅长“生成类”任务:文本续写、故事生成、对话系统(如ChatGPT)、代码生成、摘要生成、机器翻译;因其天生的自回归生成能力,GPT在生成连贯、多样化的长文本方面优势明显
- 发展历程与规模
- BERT 由Google于2018年提出,同期推出了BERT-Base(1.1亿参数)和BERT-Large(3.4亿参数)。后续虽然也有RoBERTa等变体,但BERT家族整体偏向于通过更深的双向编码器提升理解能力。
- GPT 由OpenAI提出,经历了GPT-1、GPT-2、GPT-3直到GPT-4的迭代。特别是GPT-3(1750亿参数)和后续版本,通过扩大模型规模和训练数据,展现出了强大的少样本学习和零样本泛化能力,甚至能处理从未明确训练过的任务。
# LLM训练中最消耗算力的部分是什么呢?
# 问题记录
# 模型推理部署时,Tokenizer (分词器) 为什么绝对不能跨模型混用?
大模型本质上是个数学黑盒,只认识数字向量(Token IDs)。不能混用:
- 词表映射机制不同:每个模型预训练时都有独属的字典(Vocabulary)和切词算法(如BPE、WordPiece)。 A模型字典里 ID 为1024的词是“苹果”,在B模型字典里可能是“汽车”。
- 特殊控制标记不兼容:不同模型控制文本起止、截断的特殊 Token 完全不同(如 BERT 用 [CLS],Llama 用
<s>等)。
# 深度神经网络训练时产生梯度消失的原因是什么?
梯度消失的原因:链式法则的连乘效应。神经网络更新权重依赖反向传播,本质是梯度的连乘。
使用 Sigmoid 激活函数时,其导数 f'(x) = f(x)(1-f(x)) 的最大值仅为 0.25。在深层网络(如10层)中,梯度向前传导时会经历连续相乘:0.25 * 0.25 * ... 约等于 0。=> 导致靠近输入层的梯度几乎消失,权重无法更新,网络前端像死了一样,无法提取有效特征。
ReLU 的优势(恒等映射):ReLU 函数在 x>0 时,其导数恒为 1。
无论网络有多深,只要神经元处于激活状态,梯度 1 * 1 * ... = 1,误差就能无衰减地传递回第一层。 => 深层网络的训练成为可能