 Vue深入:Virtual-DOM与Diff算法
Vue深入:Virtual-DOM与Diff算法
# Vue深入:Virtual-DOM与Diff算法
# 概念
开始之前,先来熟悉几个概念~
# DOM
文档对象模型(Document Object Model,简称DOM),它是HTML和XML文档的编程接口。它提供了对文档的结构化的表述,并定义了一种方式可以使从程序中对该结构进行访问,从而改变文档的结构,样式和内容。MDN (opens new window)
比如:
<ul id="list">
<li class="item">1111</li>
<li class="item">2222</li>
<li class="item">3333</li>
</ul>
真正的 DOM 元素是非常庞大的,因为浏览器的标准就把 DOM 设计的非常复杂,为了更直观的感受,我们可以在浏览器控制台输入以下代码,看看一个简单的div元素有哪些属性:
let oDiv = document.createElement('div');
let str = '';
for(let prop in oDiv) {
str += prop + ' ';
}
'align title lang translate dir hidden accessKey draggable spellcheck autocapitalize contentEditable isContentEditable inputMode offsetParent offsetTop offsetLeft offsetWidth offsetHeight style innerText outerText onbeforexrselect onabort onblur ......'
可以看到属性是特别多的,这样当我们频繁的去做 DOM 更新,代价肯定是比较“昂贵”的,轻微的修改可能就会导致页面重排,严重影响页面性能。
# Virtual DOM
虚拟DOM,Virtual DOM 就是一个用来描述真实DOM的javaScript对象。
如上面的真实DOM用虚拟DOM来表示:
let VNode = { // 虚拟DOM
tagName: 'ul', // 标签名
props: { // 标签属性
id: 'list'
},
children: [ // 标签子节点
{
tagName: 'li', props: { class: 'item' }, children: ['1111']
},
{
tagName: 'li', props: { class: 'item' }, children: ['2222']
},
{
tagName: 'li', props: { class: 'item' }, children: ['3333']
},
]
}
VNode 是对真实 DOM 的一种抽象描述,它的核心定义无非就几个关键属性,标签名、数据、子节点、键值等,其它属性都是用来扩展 VNode 的灵活性以及实现一些特殊 feature 的。由于 VNode 只是用来映射到真实 DOM 的渲染,不需要包含操作 DOM 的方法,因此它是非常轻量和简单的。
# 真实DOM解析流程
先看下webkit渲染引擎的工作流程图:
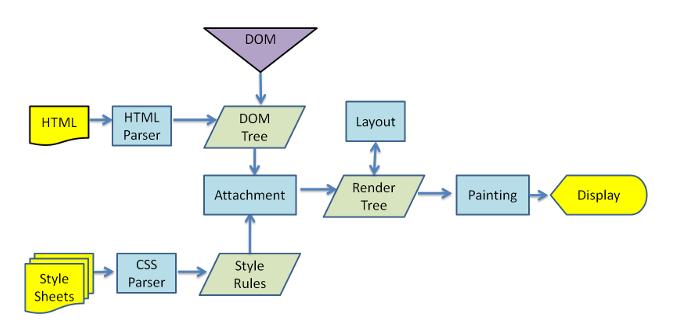
浏览器渲染引擎工作流程大致分为5步:
- 创建DOM树:用 HTML 分析器,分析 HTML 元素,构建一棵 DOM 树;
- 创建StyleRules:用 CSS 分析器,分析 CSS 文件和元素上的 inline 样式,生成页面的样式表;
- 创建Render树:将 DOM 树和样式表关联起来,构建一棵 Render 树(Attachment)。每个 DOM 节点都有 attach 方法,接受样式信息,返回一个 render 对象(又名 renderer),这些 render 对象最终会被构建成一棵 Render 树;
- 布局Layout:根据 Render 树结构,为每个 Render 树上的节点确定一个在显示屏上出现的精确坐标;
- 绘制Painting:根据 Render 树和节点显示坐标,然后调用每个节点的 paint 方法,将它们绘制出来。
- DOM 树的构建是文档加载完成开始的? 构建 DOM 树是一个渐进过程,为达到更好的用户体验,渲染引擎会尽快将内容显示在屏幕上,它不必等到整个 HTML 文档解析完成之后才开始构建 render 树和布局。
- Render 树是 DOM 树和 CSS 样式表构建完毕后才开始构建的? 这三个过程在实际进行的时候并不是完全独立的,而是会有交叉,会一边加载,一边解析,以及一边渲染。
- CSS 的解析注意点? CSS 的解析是从右往左逆向解析的,嵌套标签越多,解析越慢。
JS操作真实DOM的代价
用我们传统的开发模式,原生JS或JQ操作DOM时,浏览器会从构建DOM树开始从头到尾执行一遍流程。在一次操作中,我需要更新10个DOM节点,浏览器收到第一个DOM请求后并不知道还有9次更新操作,因此会马上执行流程,最终执行10次。例如,第一次计算完,紧接着下一个DOM更新请求,这个节点的坐标值就变了,前一次计算为无用功。计算DOM节点坐标值等都是白白浪费的性能。即使计算机硬件一直在迭代更新,操作DOM的代价仍旧是昂贵的,频繁操作还是会出现页面卡顿,影响用户体验。
虚拟DOM的好处
虚拟DOM就是为了解决浏览器性能问题而被设计出来的。如前,若一次操作中有10次更新DOM的动作,虚拟DOM不会立即操作DOM,而是将这10次更新的diff内容保存到本地一个JS对象中,最终将这个JS对象一次性attch到DOM树上,再进行后续操作,避免大量无谓的计算量。所以,用JS对象模拟DOM节点的好处是,页面的更新可以先全部反映在JS对象(虚拟DOM)上,操作内存中的JS对象的速度显然要更快,等更新完成后,再将最终的JS对象映射成真实的DOM,交由浏览器去绘制。
总结
- 避免频繁操作DOM,频繁操作DOM会可能让浏览器回流和重绘,性能也会非常低,还有就是手动操作 DOM 还是比较麻烦的,要考虑浏览器兼容性问题;
- 并不是所有情况使用虚拟DOM都提高性能,是针对在复杂的的项目使用。如果简单的操作,使用虚拟DOM要创建虚拟DOM对象等等一系列操作,还不如普通的DOM 操作;
- 虚拟DOM 可以实现跨平台渲染,服务器渲染 、小程序、原生应用都使用了虚拟DOM;
- 使用虚拟DOM改变了当前的状态不需要立即的去更新DOM,而且只对更新的内容进行更新,对于没有改变的内容不做任何操作,通过前后两次差异进行比较;
- 虚拟 DOM 可以维护程序的状态,跟踪上一次的状态。
# Diff算法
如果修改数据,真实DOM的操作是直接将整个DOM树进行重排和重绘;虚拟DOM则是先创建一个更改后的
virtual dom,然后比较更改前后的差异,只对更改的部分进行更新;这种比较前后差异的算法就是diff算法。
Diff算法是一种对比算法。对比两者是旧虚拟DOM和新虚拟DOM,对比出是哪个虚拟节点更改了,找出这个虚拟节点,并只更新这个虚拟节点所对应的真实节点,而不用更新其他数据没发生改变的节点,实现精准地更新真实DOM,进而提高效率。
复杂视图情况下使用虚拟DOM之所以提升渲染性能,是因为虚拟DOM+Diff算法可以精准找到DOM树变更的地方,减少DOM的操作(重排重绘)。
使用虚拟DOM算法的损耗计算: 总损耗 = 虚拟DOM增删改+(与Diff算法效率有关)真实DOM差异增删改+(较少的节点)排版与重绘直接操作真实DOM的损耗计算: 总损耗 = 真实DOM完全增删改+(可能较多的节点)排版与重绘
传统的Diff算法
传统的Diff算法通过循环递归对节点进行比较,然后判断每个节点的状态以及要做的操作(add,remove,change),最后 根据Virtual DOM进行DOM的渲染。大体流程如下图 (opens new window):
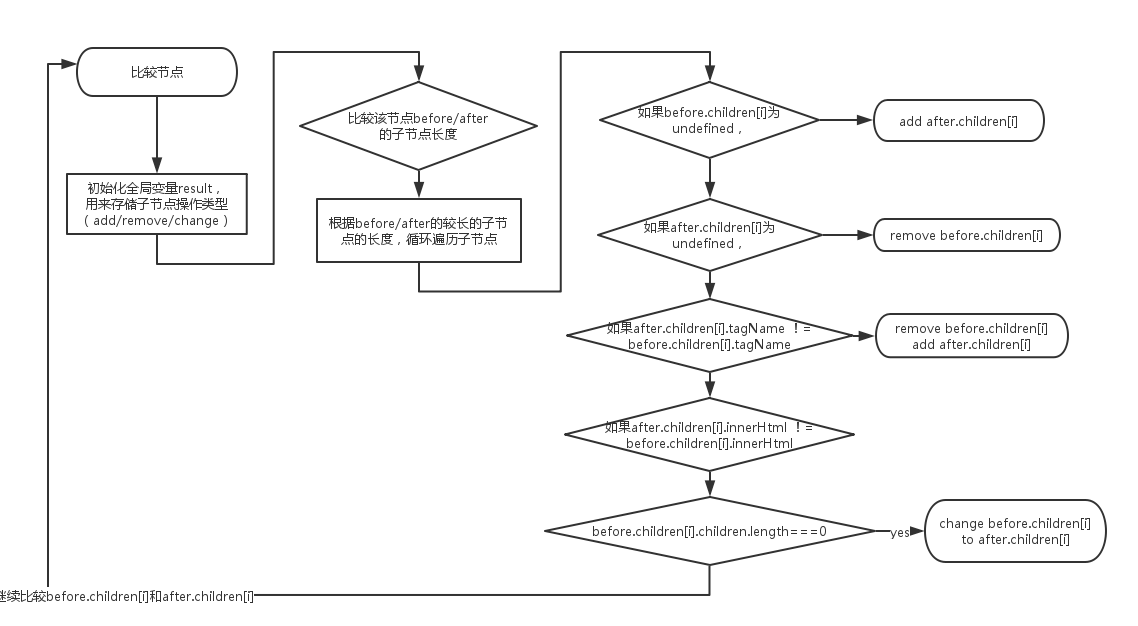
传统Diff算法的复杂度为O(n^3),这个复杂度相对来说还是较高的。后来React开发者提供了一种复杂度仅为O(n) 的Diff算法。有兴趣可点这里react的diff 从O(n^3)到 O(n) ,请问 O(n^3) 和O(n) 是怎么算出来? (opens new window)
框架层Diff算法
相较于
传统的diff算法,框架层的 diff 有个大前提假设:Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计,所以 diff 的核心就在于,它只对同层节点进行比较,忽略跨层节点的复用。
值得注意的是,同层节点的比较也不会两两进行,而是按照一定的顺序比较,或通过 key 属性判断,所以只需要遍历一次新节点,因此算法的复杂度就降低到了O(n)。
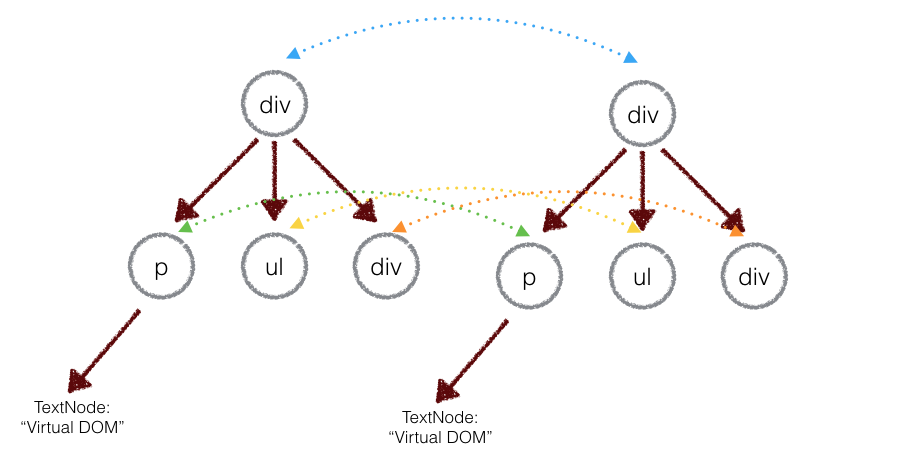
# 原理
# Simple-Virtual-Dom
首先实现一个简单版的Virtual Dom~
# 1. 将Virtual Dom对象渲染成真实Dom
Virtual Dom是一个表示真实Dom的JS对象,首先创建一个构造函数
Element,用于生成Virtual Dom对象:
// element.js
// 创建一个构造函数 Element 来表示一个 Virtual DOM
// 需要记录它的节点类型、属性,还有子节点
function Element (tagName, props, children) {
this.tagName = tagName
this.props = props
this.children = children
}
// 给 Element的原型上添加render方法,用于生成真实的dom
Element.prototype.render = function () {
var el = document.createElement(this.tagName) // 根据tagName构建
var props = this.props
for (var propName in props) { // 设置节点的DOM属性
var propValue = props[propName]
el.setAttribute(propName, propValue)
}
var children = this.children || []
children.forEach(function (child) {
var childEl = (child instanceof Element)
? child.render() // 如果子节点也是虚拟DOM,递归构建DOM节点
: document.createTextNode(child) // 如果字符串,只构建文本节点
el.appendChild(childEl)
})
return el
}
// 创建 $el 方法,用于生成一个虚拟Dom对象,返回 Element 实例
function $el (tagName, props, children) {
return new Element(tagName, props, children)
};
// 1. 创建 Virtual Dom
var ul = $el('ul', {id: 'list'}, [
$el('li', {class: 'item'}, ['Item 1']),
$el('li', {class: 'item'}, ['Item 2']),
$el('li', {class: 'item'}, ['Item 3'])
])
console.log(ul);
// 2. 将 Virtual Dom 渲染成真实 Dom
var ulRoot = ul.render()
console.log(ulRoot);
// 3. 将 渲染出来的真实 Dom 添加到页面上
document.body.appendChild(ulRoot)
梳理一下:
- 创建一个构造函数
Element来表示一个Virtual DOM对象,并在原型上添加render方法,用于渲染成真实Dom; - 然后就是创建
Virtual Dom,将Virtual Dom渲染成真实Dom,并添加到页面上。
以上只是实现了将一个
Virtual Dom渲染成真实Dom,接下来实现Virtual Dom是Diff算法:
# 2. Virtual Dom的Diff更新
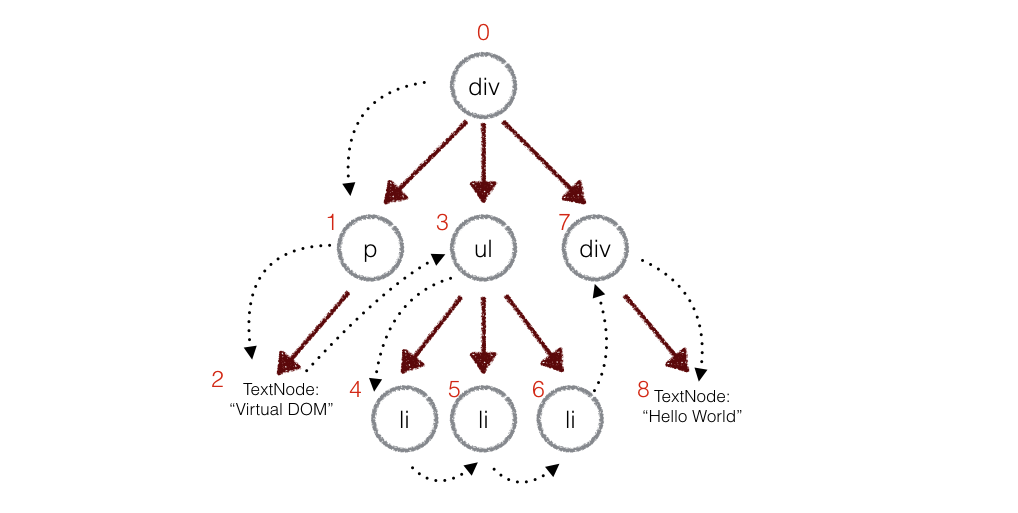
在实际的代码中,会对新旧两棵树进行一个深度优先的遍历,这样每个节点都会有一个唯一的标记:
// diff.js
import _ from './utils.js'; // 引入方法,里面会封装一些判断数据类型的方法
import patch from './patch.js'; // 引入patch中对于不同差异类型的定义
import {listDiff} from './list-diff.js'; // 这里对于list差异的判断单独封装一个方法
// diff 函数,对比两棵树,返回差异信息
export function diff (oldTree, newTree) {
var index = 0 // 当前节点的标志
var patches = {} // 用来记录每个节点差异的对象
dfsWalk(oldTree, newTree, index, patches)
return patches
}
// 对两棵树进行深度优先遍历
function dfsWalk (oldNode, newNode, index, patches) {
var currentPatch = []
// 节点被移除
if (newNode === null) {
// 无操作
} else if (_.isString(oldNode) && _.isString(newNode)) { // 都是文本节点
if (newNode !== oldNode) { // 不相同,直接替换
currentPatch.push({ type: patch.TEXT, content: newNode })
}
} else if (oldNode.tagName === newNode.tagName && oldNode.key === newNode.key) { // 节点的tabName相同,比较props和children
// 比较属性差异
var propsPatches = diffProps(oldNode, newNode)
if (propsPatches) {
currentPatch.push({ type: patch.PROPS, props: propsPatches })
}
// 比较子节点差异
if (!isIgnoreChildren(newNode)) {
diffChildren(
oldNode.children,
newNode.children,
index,
patches,
currentPatch
)
}
// 节点tabName不相同,直接替换
} else {
currentPatch.push({ type: patch.REPLACE, node: newNode })
}
if (currentPatch.length) { // 如果有差异,在 patches 中进行标记
patches[index] = currentPatch
}
}
// 比较子节点
function diffChildren (oldChildren, newChildren, index, patches, currentPatch) {
// 用 listDiff 的 列表对比算法 比较子节点差异
// 因为tagName是可重复的,所以需要给子节点加上唯一标识key,列表对比的时候,使用key进行对比,这样才能复用老的 DOM 树上的节点。
var diffs = listDiff(oldChildren, newChildren, 'key')
newChildren = diffs.children
if (diffs.moves.length) { // 子节点存在差异
var reorderPatch = { type: patch.REORDER, moves: diffs.moves }
currentPatch.push(reorderPatch)
}
var leftNode = null; // 记录左边节点
var currentNodeIndex = index
// 遍历旧子节点
_.each(oldChildren, function (child, i) {
var newChild = newChildren[i]
// 获取深度优先遍历后,当前节点下标
currentNodeIndex = leftNode && leftNode.count ? currentNodeIndex + leftNode.count + 1 : currentNodeIndex + 1;
// 递归执行dfsWalk,继续对子节点进行差异比较
dfsWalk(child, newChild, currentNodeIndex, patches);
leftNode = child;
})
}
// 比较属性差异
function diffProps (oldNode, newNode) {
var count = 0
var oldProps = oldNode.props
var newProps = newNode.props
var key, value
var propsPatches = {}
// 找出属性差异
for (key in oldProps) {
value = oldProps[key]
if (newProps[key] !== value) {
count++
propsPatches[key] = newProps[key]
}
}
// 循环新属性
for (key in newProps) {
value = newProps[key]
if (!oldProps.hasOwnProperty(key)) {
count++
propsPatches[key] = newProps[key]
}
}
if (count === 0) {
return null
}
return propsPatches
}
// 是否不需要比较子节点差异
function isIgnoreChildren (node) {
return (node.props && node.props.hasOwnProperty('ignore'))
}
- 总结:
- 首先执行
diff方法,对oldTree和newTree进行比较,接着执行dfsWalk,对新旧节点进行深度优先遍历; - 在
dfsWalk中会对比新旧节点的不同,记录下来;这里节点的差异类型主要有四种:
REPLACE = 0:替换掉原来的节点,例如把上面的div换成了sectionREORDER = 1:移动、删除、新增子节点,例如上面div的子节点,把p和ul顺序互换PROPS = 2:修改了节点的属性TEXT = 3:对于文本节点,文本内容可能会改变。例如修改上面的文本节点2内容为Virtual DOM 2
- 判断之后,如果确实存在差异,将节点的差异记录在
patches[index]中;上面的
div和新的div有差异,当前的标记是0,那么:patches[0] = [{difference}, {difference}, ...];同理p是patches[1],ul是patches[3],类推。 - 同时通过
diffChildren对子节点进行比较,并对子节点遍历进行执行dfsWalk;通过diffProps比较节点属性差异;注意需要注意的是:在子节点列表对比中,因为tagName是可重复的,所以需要给子节点加上唯一标识
key,列表对比的时候,使用key进行对比,这样才能复用老的DOM树上的节点。 - 这样,我们就可以通过深度优先遍历两棵树,每层的节点进行对比,记录下每个节点的差异了。
列表对比算法
子节点的对比算法,例如
p, ul, div的顺序换成了div, p, ul。这个该怎么对比?如果按照同层级进行顺序对比的话,它们都会被替换掉。如p和div的tagName不同,p会被div所替代。最终,三个节点都会被替换,这样DOM开销就非常大。而实际上是不需要替换节点,而只需要经过节点移动就可以达到,我们只需知道怎么进行移动。
将这个问题抽象出来其实就是字符串的最小编辑距离问题(Edition Distance),最常见的解决方法是 Levenshtein Distance, Levenshtein Distance是一个度量两个字符序列之间差异的字符串度量标准,两个单词之间的Levenshtein Distance是将一个单词转换为另一个单词所需的单字符编辑(插入、删除或替换)的最小数量。Levenshtein Distance通过动态规划求解,时间复杂度为O(M*N)。该算法的具体实现细节可参考这里 (opens new window)。
# 3. 把差异应用到真正的DOM树上
可以对已经渲染出来的旧DOM树进行深度优先的遍历,遍历的时候传入上一步骤通过diff算法生成的差异信息patches对象:
// patch.js
import _ from './utils.js';
// 差异类型
var REPLACE = 0 // 替换原有节点
var REORDER = 1 // 移动、删除、新增子节点
var PROPS = 2 // 修改了节点的属性
var TEXT = 3 // 文本节点
/**
*
* @param {*} node 旧虚拟Dom渲染出来的DOM树
* @param {*} patches 新旧虚拟dom的差异
*/
function patch (node, patches) {
var walker = {index: 0}
dfsWalk(node, walker, patches)
}
// 对已经渲染出来的Dom进行深度优先遍历
function dfsWalk (node, walker, patches) {
var currentPatches = patches[walker.index] // 获取当前节点的修改
var len = node.childNodes ? node.childNodes.length : 0;
// 对子节点进行遍历
for (var i = 0; i < len; i++) {
var child = node.childNodes[i]
walker.index++
dfsWalk(child, walker, patches) // 递归操作
}
if (currentPatches) { // 如果确实有差异
console.log('===1234',node, currentPatches);
applyPatches(node, currentPatches)
}
}
// 对有差异的节点进行更新
function applyPatches (node, currentPatches) {
// 遍历当前节点的差异信息
_.each(currentPatches, function (currentPatch) {
// 判断差异信息类型
switch (currentPatch.type) {
case REPLACE: // 替换
// 如果node是字符串,则生成文本;不然node就是虚拟dom,直接将其生成真实dom
var newNode = (typeof currentPatch.node === 'string') ? document.createTextNode(currentPatch.node) : currentPatch.node.render()
node.parentNode.replaceChild(newNode, node) // 直接进行替换
break
case REORDER: // 新增、删除
reorderChildren(node, currentPatch.moves)
break
case PROPS: // 属性
setProps(node, currentPatch.props) // 更新属性
break
case TEXT: // 文本
if (node.textContent) {
node.textContent = currentPatch.content
} else { // 兼容ie
node.nodeValue = currentPatch.content
}
break
default:
throw new Error('Unknown patch type ' + currentPatch.type)
}
})
}
// 设置属性
function setProps (node, props) {
for (var key in props) {
if (props[key] === void 666) {
node.removeAttribute(key)
} else {
var value = props[key]
_.setAttr(node, key, value)
}
}
}
// 更新子节点
function reorderChildren (node, moves) {
console.log('===node', node);
var staticNodeList = _.toArray(node.childNodes)
var maps = {}
_.each(staticNodeList, function (node) {
if (node.nodeType === 1) {
var key = node.getAttribute('key') // 获取节点key值
if (key) {
maps[key] = node
}
}
})
_.each(moves, function (move) {
var index = move.index
if (move.type === 0) { // 删除节点
if (staticNodeList[index] === node.childNodes[index]) { // maybe have been removed for inserting
node.removeChild(node.childNodes[index])
}
staticNodeList.splice(index, 1) // 删除
} else if (move.type === 1) { // 插入节点
var insertNode = maps[move.item.key]
? maps[move.item.key].cloneNode(true) // 复用老节点
: (typeof move.item === 'object')
? move.item.render()
: document.createTextNode(move.item)
staticNodeList.splice(index, 0, insertNode)
node.insertBefore(insertNode, node.childNodes[index] || null)
}
})
}
patch.REPLACE = REPLACE
patch.REORDER = REORDER
patch.PROPS = PROPS
patch.TEXT = TEXT
export default patch
在dfsWalk方法中对已经渲染出来的Dom进行深度优先遍历,同时在applyPatches中对有差异的节点进行更新。
# 4. 使用
以上Virtual DOM算法主要是实现上面步骤的三个函数:element,diff,patch。然后就可以实际的进行使用:
// index.js
import $el from './element.js';
import {diff} from './diff.js';
import patch from './patch.js';
// 1. 创建 Virtual Dom
var ul = $el('div', {'id': 'container'}, [
$el('h1', {style: 'color: blue'}, ['h1 virtal dom']),
$el('p', ['p virtual-dom']),
$el('ul', [$el('li', ['li virtual dom'])])
])
/** 节点梳理
* - div 0
* - h1 1
* - 'h1 virtal dom' 2
* - p 3
* - 'p virtual-dom' 4
* - ul 5
* - li 6
* - 'li virtual dom' 7
*/
console.log(ul);
// 2. 将 Virtual Dom 渲染成真实 Dom
var ulRoot = ul.render()
console.log(ulRoot);
// 3. 将 渲染出来的真实 Dom 添加到页面上
document.body.appendChild(ulRoot);
document.getElementById('btn').addEventListener('click', function() {
// 4. 生成新的虚拟DOM
var newUl =$el('div', {'id': 'container'}, [
$el('h1', {style: 'color: red'}, ['h1 virtal dom']),
$el('p', ['p virtual-dom v2']),
$el('ul', [$el('li', {class: "item"}, ['li virtual dom']), $el('li', ['li2 virtual dom'])])
])
/** 节点梳理
* - div 0
* - h1 1
* - 'h1 virtal dom' 2
* - p 3
* - 'p virtual-dom' 4
* - ul 5
* - li 6
* - 'li virtual dom' 7
* - li 8
* - 'li2 virtual dom' 9
*/
console.log('====newUl', newUl);
// 5. 比较两棵虚拟DOM树的不同
var patches = diff(ul, newUl)
console.log('====patches', patches);
// 6. 在真正的DOM元素上应用变更
patch(ulRoot, patches);
})
上述实现方法的完整代码详见这里 (opens new window)~
以上关于Virtual Dom算法的实现参考了这篇博文深度剖析:如何实现一个 Virtual DOM 算法 (opens new window)~
# Vue中Virtual Dom
接下来看看Vue中的Virtual Dom是怎么实现的,首先从github (opens new window)上把Vue的源码clone下来,这里分析的Vue源码版本为2.6.14~
# VNode
在Vue.js中,Virtual DOM是用VNode来描述,具体定义在源码src/core/vdom/vnode.js中:
// src/core/vdom/vnode.js
export default class VNode {
tag: string | void;
data: VNodeData | void;
children: ?Array<VNode>;
text: string | void;
elm: Node | void;
ns: string | void;
context: Component | void; // rendered in this component's scope
key: string | number | void;
componentOptions: VNodeComponentOptions | void;
componentInstance: Component | void; // component instance
parent: VNode | void; // component placeholder node
...
constructor (
tag?: string,
data?: VNodeData,
children?: ?Array<VNode>,
text?: string,
elm?: Node,
context?: Component,
componentOptions?: VNodeComponentOptions,
asyncFactory?: Function
) {
this.tag = tag
this.data = data
this.children = children
this.text = text
this.elm = elm
this.ns = undefined
...
}
// DEPRECATED: alias for componentInstance for backwards compat.
/* istanbul ignore next */
get child (): Component | void {
return this.componentInstance
}
}
源码中对于VNode的定义较为复杂一些,因为它这里包含了很多Vue.js的特性;实际上Vue.js中Virtual DOM是借鉴了一个开源库snabbdom (opens new window)的实现,然后加入了一些Vue.js的一些特性。
这里的核心属性有:
tag属性即这个vnode的标签属性data属性包含了最后渲染成真实dom节点后,节点上的class,attribute,style以及绑定的事件children属性是vnode的子节点text属性是文本属性elm属性为这个vnode对应的真实dom节点key属性是vnode的标记,在diff过程中可以提高diff的效率
Virtual DOM除了它的数据结构的定义,映射到真实的DOM实际上要经历VNode的create、diff、patch等过程。
# VNode的创建
Vue.js 利用 _createElement 方法创建 VNode,它定义在src/core/vdom/create-element.js中:
// src/core/vdom/create-element.js
export function _createElement (
context: Component,
tag?: string | Class<Component> | Function | Object,
data?: VNodeData,
children?: any,
normalizationType?: number
): VNode | Array<VNode> {
// 省略部分非主线代码
if (normalizationType === ALWAYS_NORMALIZE) {
children = normalizeChildren(children)
} else if (normalizationType === SIMPLE_NORMALIZE) {
children = simpleNormalizeChildren(children)
}
let vnode, ns
// 这里先对 tag 做判断,如果是 string 类型
if (typeof tag === 'string') {
let Ctor
ns = (context.$vnode && context.$vnode.ns) || config.getTagNamespace(tag)
if (config.isReservedTag(tag)) { // 判断如果是内置的一些节点,则直接创建一个普通 VNode
// 创建虚拟Vnode
vnode = new VNode(
config.parsePlatformTagName(tag), data, children,
undefined, undefined, context
)
// 如果是为已注册的组件名,则通过 createComponent 创建一个组件类型的 VNode
} else if ((!data || !data.pre) && isDef(Ctor = resolveAsset(context.$options, 'components', tag))) {
vnode = createComponent(Ctor, data, context, children, tag)
} else { // 否则创建一个未知的标签的 VNode
vnode = new VNode(
tag, data, children,
undefined, undefined, context
)
}
} else { // 如果是 tag 一个 Component 类型,则直接调用 createComponent 创建一个组件类型的 VNode 节点。
vnode = createComponent(tag, data, context, children)
}
...
}
_createElement 方法有 5 个参数:
context表示VNode的上下文环境,它是Component类型;tag表示标签,它可以是一个字符串,也可以是一个Component;data表示VNode的数据,它是一个VNodeData类型,可以在flow/vnode.js中找到它的定义;children表示当前VNode的子节点,它是任意类型的,它接下来需要被规范为标准的VNode数组;normalizationType表示子节点规范的类型,类型不同规范的方法也就不一样,它主要是参考render函数是编译生成的还是用户手写的。
至此,我们大致了解了
createElement创建VNode的过程,每个VNode有children,children每个元素也是一个VNode,这样就形成了一个VNode Tree,它很好的描述了我们的DOM Tree。
# update
Vue.js 源码实例化了一个 watcher,一旦 model 中的响应式的数据发生了变化,这些响应式的数据所维护的 dep 数组便会调用 dep.notify() 完成所有依赖遍历执行的工作,这包括视图的更新,即 updateComponent 方法的调用:
// src/core/instance/lifecycle.js
export function mountComponent (
vm: Component,
el: ?Element,
hydrating?: boolean
): Component {
vm.$el = el
callHook(vm, 'beforeMount')
let updateComponent
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
updateComponent = () => {
const vnode = vm._render() // 生成Vnode
vm._update(vnode, hydrating) // 更新
}
} else {
updateComponent = () => {
vm._update(vm._render(), hydrating)
}
}
// 实例化一个渲染Watcher,在它的回调函数中会调用 updateComponent 方法
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) {
callHook(vm, 'beforeUpdate')
}
}
}, true)
hydrating = false
return vm
}
完成视图的更新工作事实上就是调用了vm._update方法,这个方法接收的第一个参数是刚生成的VNode:
// src/core/instance/lifecycle.js
Vue.prototype._update = function (vnode: VNode, hydrating?: boolean) {
...
// 核心代码,
if (!prevVnode) { // 初始化
vm.$el = vm.__patch__(vm.$el, vnode, hydrating, false /* removeOnly */)
} else { // 更新
vm.$el = vm.__patch__(prevVnode, vnode)
}
...
}
在这个方法当中核心的就是vm.__patch__方法,主要完成了prevVnode 和 vnode 的 diff 过程并根据需要操作的 vdom 节点打 patch,最后生成新的真实 dom 节点并完成视图的更新工作。
# patch
patch函数是 diff 流程的入口函数;当数据改变时,会触发setter,并且通过Dep.notify去通知所有订阅者Watcher,订阅者们就会调用patch方法,给真实DOM打补丁,更新相应的视图。
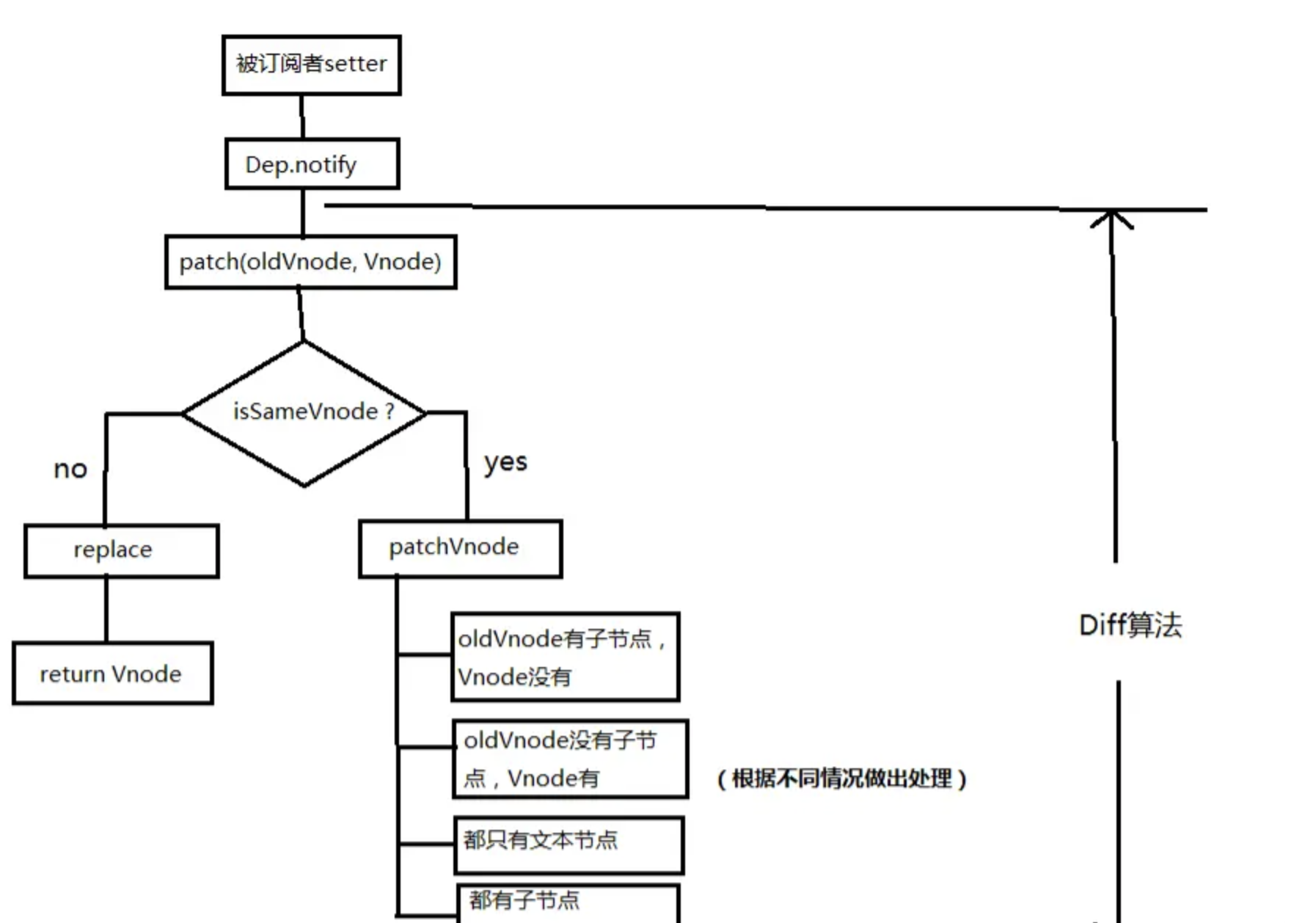
vm.__patch__ 方法定义在 src/core/vdom/patch.js 中:
// src/core/vdom/patch.js
function patch (oldVnode, vnode, hydrating, removeOnly) {
......
if (isUndef(oldVnode)) {
// 当oldVnode不存在时,创建新的节点
isInitialPatch = true
createElm(vnode, insertedVnodeQueue)
} else {
// 对oldVnode和vnode进行diff,并对oldVnode打patch
const isRealElement = isDef(oldVnode.nodeType)
// 只有当基本属性相同的情况下才认为这个2个vnode 只是局部发生了更新,然后才会对这2个 vnode 进行 diff
if (!isRealElement && sameVnode(oldVnode, vnode)) {
patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly)
} else { // 2个 vnode 的基本属性存在不一致的情况,那么就会直接跳过 diff 的过程
...
createElm( // 据 vnode 新建一个真实的 dom
vnode,
insertedVnodeQueue,
oldElm._leaveCb ? null : parentElm,
nodeOps.nextSibling(oldElm)
)
...
if (isDef(parentElm)) {
removeVnodes([oldVnode], 0, 0) // 删除老节点
} else if (isDef(oldVnode.tag)) {
invokeDestroyHook(oldVnode)
}
}
......
}
}
- sameVnode
patch关键的一步就是sameVnode方法判断是否为同一类型节点:
// src/core/vdom/patch.js
function sameVnode (a, b) {
return (
a.key === b.key && // key值是否一样
a.asyncFactory === b.asyncFactory && (
(
a.tag === b.tag && // 签名是否一样
a.isComment === b.isComment && // 是否都为注释点
isDef(a.data) === isDef(b.data) && // 是否都定义了data
sameInputType(a, b) // 当标签为input时,type必须是否相同
) || (
isTrue(a.isAsyncPlaceholder) &&
isUndef(b.asyncFactory.error)
)
)
)
}
# patchVnode
diff 过程中主要是通过调用 patchVnode 方法进行的:
// src/core/vdom/patch.js
function patchVnode ( oldVnode, vnode, insertedVnodeQueue, ownerArray, index,removeOnly) {
if (oldVnode === vnode) { // 如果新旧虚拟节点是同一个对象,则终止
return
}
...
const elm = vnode.elm = oldVnode.elm // 获取真实DOM对象
// 获取新旧虚拟节点的子节点数组
const oldCh = oldVnode.children
const ch = vnode.children
// 如果vnode没有文本节点
if (isUndef(vnode.text)) {
// 如果oldVnode的children属性存在且vnode的children属性也存在
if (isDef(oldCh) && isDef(ch)) {
// updateChildren,对子节点进行diff
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) { // 只有新节点有children
// 如果oldVnode的text存在,那么首先清空text的内容,然后将vnode的children添加进去
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) { // 只有旧节点有children,// 删除elm下的oldchildren
removeVnodes(oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) { // oldVnode有子节点,而vnode没有,那么就清空这个节点
nodeOps.setTextContent(elm, '')
}
} else if (oldVnode.text !== vnode.text) { // 如果oldVnode和vnode文本属性不同,那么直接更新真实dom节点的文本元素
nodeOps.setTextContent(elm, vnode.text)
}
}
oldCh 为 oldVnode的子节点,ch 为 Vnode的子节点,diff流程如下:
- 首先进行文本节点的判断,若
oldVnode.text !== vnode.text,那么就会直接进行文本节点的替换; - 在
vnode没有文本节点的情况下,进入子节点的diff;- 当
oldCh和ch都存在且不相同的情况下,调用updateChildren对子节点进行diff; - 若
oldCh不存在,ch存在,首先清空oldVnode的文本节点,同时调用addVnodes方法将ch添加到真实domelm节点当中; - 若
oldCh存在,ch不存在,则删除elm真实节点下的oldCh子节点; - 若
oldVnode有文本节点,而vnode没有,那么就清空这个文本节点。
- 当
# updateChildren
这里着重分析下updateChildren方法,它也是整个 diff 过程中最重要的环节:
// src/core/vdom/patch.js
function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
// 为oldCh和newCh分别建立索引,为之后遍历的依据
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0] // 旧节点首指针
let oldEndVnode = oldCh[oldEndIdx] // 旧节点尾指针
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0] // 新节点首指针
let newEndVnode = newCh[newEndIdx] // 新节点尾指针
let oldKeyToIdx, idxInOld, vnodeToMove, refElm
// 直到oldCh或者newCh被遍历完后跳出循环
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
// 插入到老的开始节点的前面
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 如果以上条件都不满足,那么这个时候开始比较key值,首先建立key和index索引的对应关系
// createKeyToOldIdx方法,用以将oldCh中的key属性作为键,而对应的节点的索引作为值。然后再判断在newStartVnode的属性中是否有key,且是否在oldKeyToIndx中找到对应的节点。
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
// 如果idxInOld不存在
// 1. newStartVnode上存在这个key,但是oldKeyToIdx中不存在
// 2. newStartVnode上并没有设置key属性
if (isUndef(idxInOld)) { // New element
// 创建新的dom节点
// 插入到oldStartVnode.elm前面
// 参见createElm方法
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
} else {
vnodeToMove = oldCh[idxInOld]
// 将找到的key一致的oldVnode再和newStartVnode进行diff
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
oldCh[idxInOld] = undefined
// 移动node节点
canMove && nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm)
} else {
// same key but different element. treat as new element
// 创建新的dom节点
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
// 如果最后遍历的oldStartIdx大于oldEndIdx的话
if (oldStartIdx > oldEndIdx) { // 如果是老的vdom先被遍历完
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
// 添加newVnode中剩余的节点到parentElm中
addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
} else if (newStartIdx > newEndIdx) { // 如果是新的vdom先被遍历完,则删除oldVnode里面所有的节点
// 删除剩余的节点
removeVnodes(oldCh, oldStartIdx, oldEndIdx)
}
}
上面代码略显复杂,其实这里用到的是一种叫做首尾指针法的对比方法,新的子节点集合和旧的子节点集合,各有首尾两个指针。
新旧两个子节点的首尾指针分别为:oldStartVnode、oldEndVnode和newStartVnode、newEndVnode,会进行互相进行比较。
总共有五种比较情况:
oldStartVnode和newStartVnode使用sameVnode方法进行比较,sameVnode(oldStartVnode, newStartVnode)oldStartVnode和newEndVnode使用sameVnode方法进行比较,sameVnode(oldStartVnode, newEndVnode)oldEndVnode和newStartVnode使用sameVnode方法进行比较,sameVnode(oldEndVnode, newStartVnode)oldEndVnode和newEndVnode使用sameVnode方法进行比较,sameVnode(oldEndVnode, newEndVnode)- 如果以上逻辑都匹配不到,再把所有旧子节点的
key做一个映射到旧节点下标的key -> index表,然后用新vnode的key去找出在旧节点中可以复用的位置。
接下来分析下整个diff流程:
- 无
key的情况:
- 首先从第一个节点开始比较,不管是
oldCh还是newCh的起始或者终止节点都不存在sameVnode,同时节点属性中是不带key标记的,因此第一轮的diff完后,newCh的startVnode被添加到oldStartVnode的前面,同时newStartIndex前移一位;

- 第二轮的
diff中,满足sameVnode(oldStartVnode, newStartVnode),因此对这2个vnode进行diff,最后将patch打到oldStartVnode上,同时oldStartVnode和newStartIndex都向前移动一位;
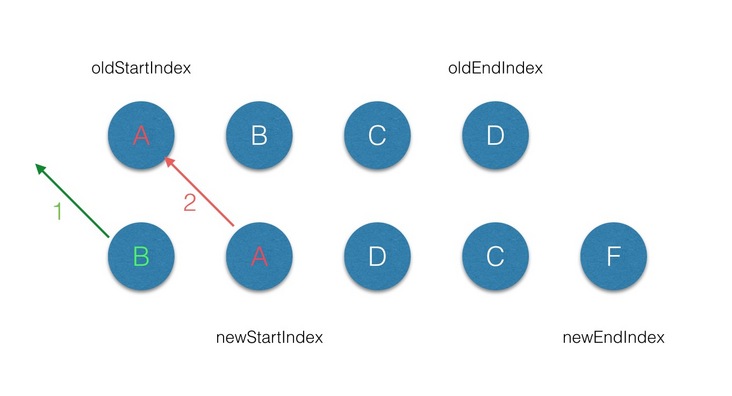
- 第三轮的
diff中,满足sameVnode(oldEndVnode, newStartVnode),那么首先对oldEndVnode和newStartVnode进行diff,并对oldEndVnode进行patch,并完成oldEndVnode移位的操作,最后newStartIndex前移一位,oldStartVnode后移一位;
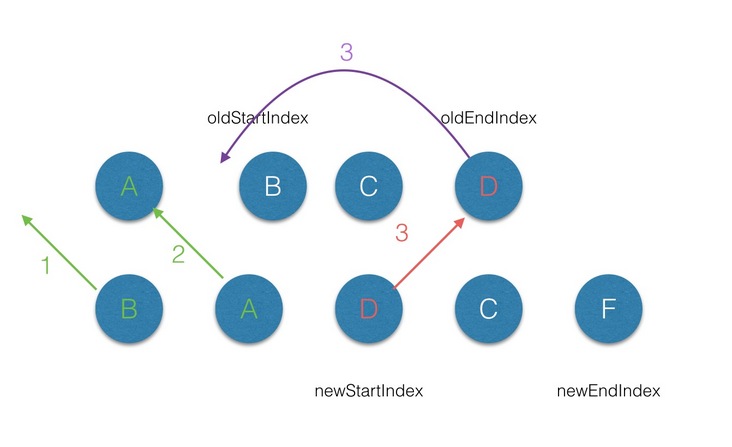
- 第四轮的
diff中,过程同步骤3;
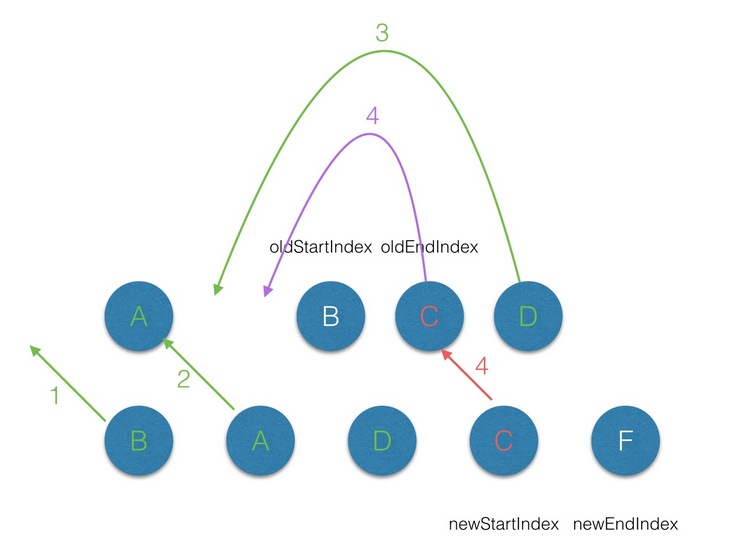
- 第五轮的
diff中,同过程1;
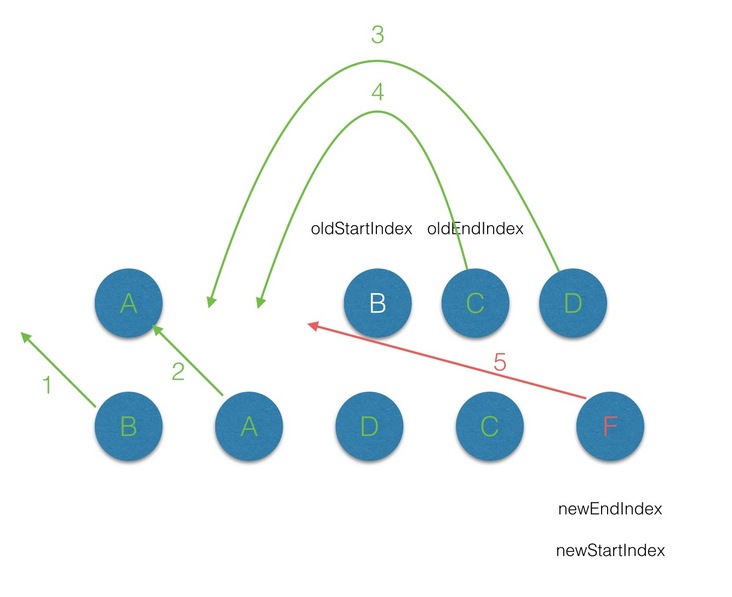
- 遍历的过程结束后,
newStartIdx > newEndIdx,说明此时oldCh存在多余的节点,那么最后就需要将这些多余的节点删除
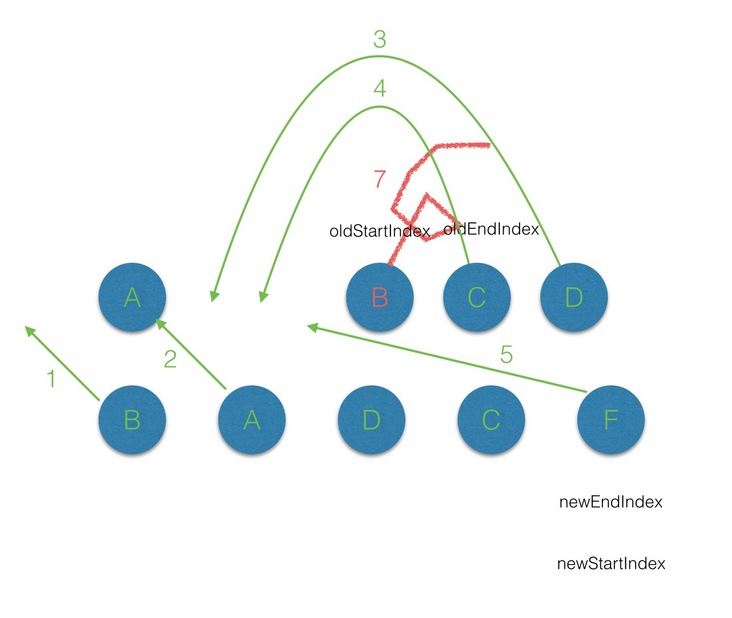
- 有
key的情况:
在 vnode 不带 key 的情况下,每一轮的 diff 过程当中都是起始和结束节点进行比较,直到 oldCh 或者 newCh 被遍历完。而当为 vnode 引入 key 属性后,在每一轮的 diff 过程中,当起始和结束节点都没有找到 sameVnode 时,然后再判断在 newStartVnode 的属性中是否有 key,且是否在 oldKeyToIndx 中找到对应的节点:
- 如果不存在这个
key,那么就将这个newStartVnode作为新的节点创建且插入到原有的root的子节点中; - 如果存在这个
key,那么就取出oldCh中的存在这个key的vnode,然后再进行diff的过;
通过以上分析,给
vdom上添加key属性后,遍历diff的过程中,当起始点, 结束点的搜寻及diff出现还是无法匹配的情况下时,就会用key来作为唯一标识,来进行diff,这样就可以提高diff效率。
流程分析
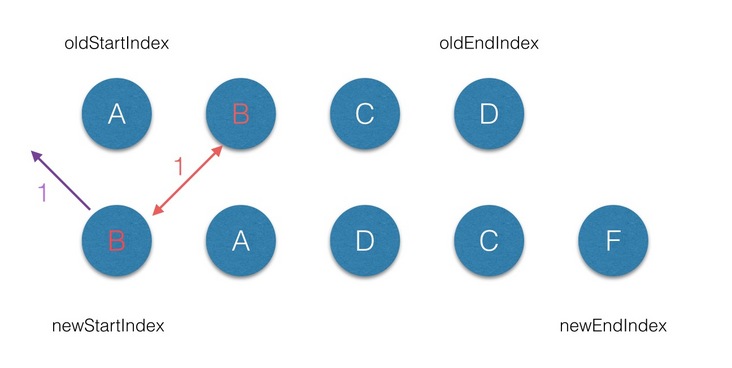
- 首先从第一个节点开始比较,不管是
oldCh还是newCh的起始或者终止节点都不存在sameVnode,但节点属性中是带key标记的, 然后在oldKeyToIndx中找到对应的节点,这样第一轮diff过后oldCh上的B节点被删除了,但是newCh上的B节点上elm属性保持对oldCh上 B节点 的elm引用。
- 第二轮的
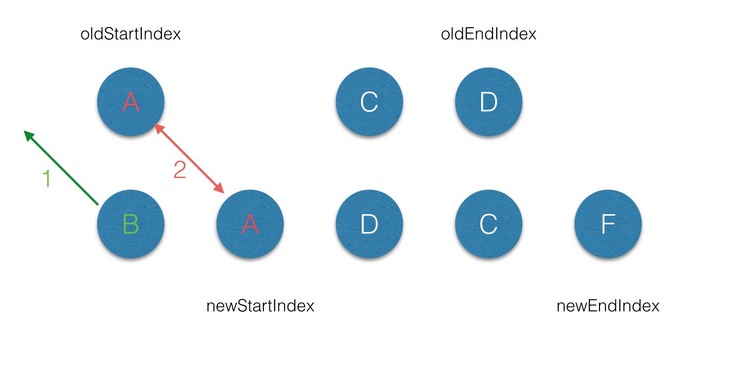
diff中,满足sameVnode(oldStartVnode, newStartVnode),因此对这2个vnode进行diff,最后将patch打到oldStartVnode上,同时oldStartVnode和newStartIndex都向前移动一位 ;
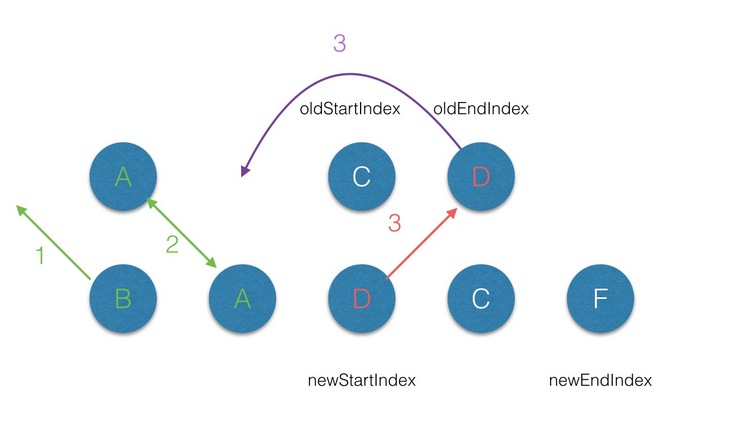
- 第三轮的
diff中,满足sameVnode(oldEndVnode, newStartVnode),那么首先对oldEndVnode和newStartVnode进行diff,并对oldEndVnode进行patch,并完成oldEndVnode移位的操作,最后newStartIndex前移一位,oldStartVnode后移一位;
- 第四轮的
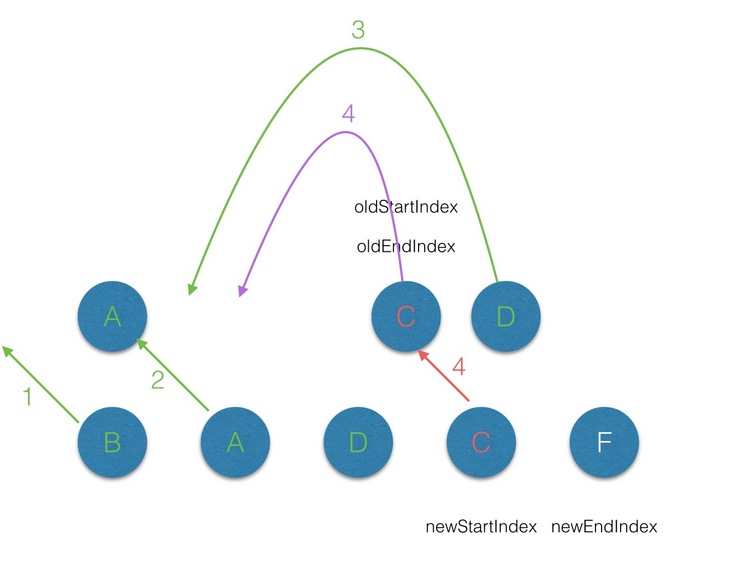
diff中,过程同步骤2;
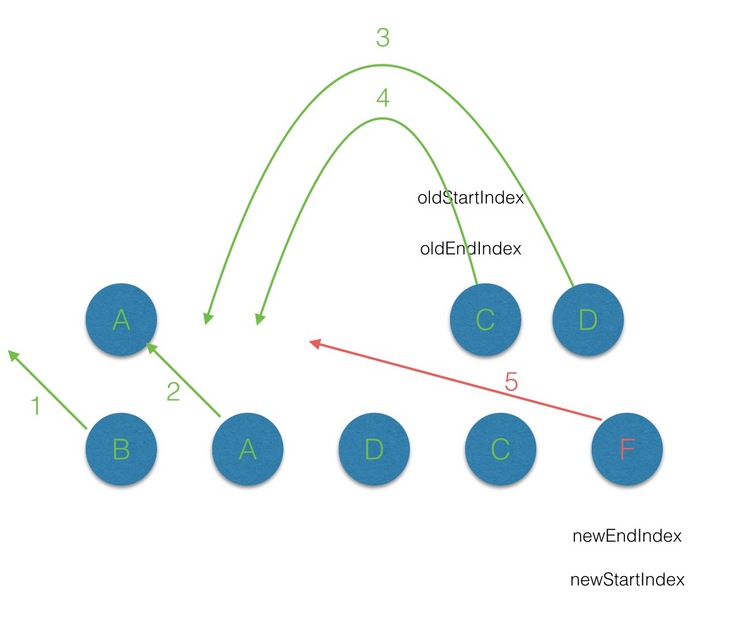
- 第五轮的
diff中,因为此时oldStartIndex已经大于oldEndIndex,所以将剩余的Vnode队列插入队列最后。
# 思考
Q: 平常v-for循环渲染的时候,为什么不建议用index作为循环项的key呢?
先看个例子,左边是初始数据,然后在数据前插入一个新数据,变成右边的列表:
// oldDom newDom
<ul> <ul>
<li key="0">a</li> <li key="0">林三心</li>
<li key="1">b</li> <li key="1">a</li>
<li key="2">c</li> <li key="2">b</li>
<li key="3">c</li>
</ul> </ul>
理想的情况是:只插入一个li标签新节点,其他都不动,确保操作DOM效率最高。
但如果用index做key的话,会看到所有li标签都会更新;为什么呢?分析一下:
在
patch方法中,在进行子节点的diff算法过程中,会进行旧首节点和新首节点的sameNode对比,这一步命中了逻辑,因为现在新旧两次首部节点 的key都是0了,同理,key为1和2的也是命中了逻辑,导致相同key的节点会去进行patchVnode更新文本,而原本就有的c节点,却因为之前没有key为4的节点,而被当做了新节点;所以使用index做key,最后新增的居然是本来就已有的c节点,而前三个都进行patchVnode更新文本,最后一个进行了新增,那就解释了为什么所有li标签都更新了。
可以通过给li标签设置一个唯一的
key解决上面的问题。因为设置之后,a,b,c节点的key就会是永远不变的,更新前后key都是一样的,并且又由于a,b,c节点的内容本来就没变,所以就算是进行了patchVnode,也不会执行里面复杂的更新操作,节省了性能,而林三心节点,由于更新前没有他的key所对应的节点,所以他被当做新的节点,增加到真实DOM上去了。
# 对比
关于react与vue的diff算法的对比可以参考这篇文章React、Vue2、Vue3的三种Diff算法 (opens new window)
# 参考
- Vue.js 技术揭秘 (opens new window)
- 深度剖析:如何实现一个 Virtual DOM 算法 (opens new window)
- 深入剖析:Vue核心之虚拟DOM (opens new window)
- 15张图,20分钟吃透Diff算法核心原理,我说的!!! (opens new window)
- 从了解到深入虚拟DOM和实现diff算法 (opens new window)
- 手写一个虚拟DOM库,彻底让你理解diff算法 (opens new window)