 浅拷贝与深拷贝
浅拷贝与深拷贝
# 浅拷贝与深拷贝
这里是我的浅拷贝和深拷贝的学习记录。
# 开始之前
开始之前,先梳理几个基本概念。
# js的的数据类型
JS中的数据类型主要分为基本数据类型和引用数据类型。
基本数据类型
- ES5之前基本数据类型主要包括:
String、Number、Boolean、Null、undifiend五种; - ES6又新增了一种新的基本数据类型:Symbol (opens new window),表示独一无二的值;
- 在JavaScript中,
Number可以准确表达的最大数字是253,现在ES10又新增了一种新的数据类型BigInt (opens new window),用于表示大于2^53 - 1的整数,BigInt可以表示任意大的整数,V8引擎v6.7默认启用对 BigInt 的支持。
- ES5之前基本数据类型主要包括:
引用数据类型
引用数据类型主要包括:
Object、Array、Function、Date、RegExp等复杂数据类型,包括ES6新增的Map、Set等;js的引用数据类型本质上都是对象类型。
基本数据类型是存在栈内存中的,引用类型是存在堆内存中的,但是引用类型的引用还是存在栈内存中的。关于堆内存和栈内存的介绍我在js的事件循环中有过讲解,这里不再赘述。
# 赋值、浅拷贝、和深拷贝
这里先梳理下赋值、浅拷贝、和深拷贝的区别。
# 赋值(copy)
对于基本数据类型来说,当我们进行赋值操作=时,实际上是在内存中新开一段栈内存,然后再将值赋值到新的栈中:
let a = 1
let b = a
a = 5
console.log(a) // 5
console.log(b) // 1
赋值之后两个变量互不影响。
而对于引用数据类型来说,在进行赋值操作时,实际上是按址传递:把变量的地址传给了另一个变量,所以称为传址。传址之后,两个变量就指向同一个地址,两者的操作是互有影响的。
let a = {name: 'tom'};
let b = a;
a.name = 'rose';
console.log(a.name); // rose
console.log(b.name); // rose
# 浅拷贝与深拷贝
- 什么是浅拷贝(shallow-copy)?
创建一个新对象,该对象拥有原始对象第一层属性的精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址 ,所以如果其中一个对象改变了这个地址,就会影响到另一个对象。
var a = [1,[2,3],4];
var b= [];
// 浅拷贝
for (var i in a){
b[i] = a[i]
}
a[0] = 5
a[1][1] = 6
console.log(a) // [5, [2, 6], 4]
console.log(b) // [1, [2, 6], 4]
以上b对象对a对象实现了一个浅拷贝,a[0]是一个基本数据类型Number,所以更改互不影响;a[1]是一个对象,所以里面的修改会互相影响。
- 什么是深拷贝(deep-copy)?
创建一个新对象,该对象有着对原始对象所有层级属性的递归精确拷贝。将一个对象从内存中完整的拷贝一份出来,从堆内存中开辟一个新的区域存放新对象,且修改新对象不会影响原对象。
var a = [1,[2,3],4];
var b = JSON.parse(JSON.stringify(a)); // 深拷贝
a[0] = 5
a[1][1] = 6
console.log(a) // [5, [2, 6], 4]
console.log(b) // [1, [2, 3], 4]
深拷贝之后,原对象a的修改就不会影响目标对象b。
提示
- 对于基本数据类型来说,不存在赋值、深浅拷贝这个问题,每次赋值都相当于是一次深拷贝;深拷贝和浅拷贝都是针对js的引用数据类型。
- 浅拷贝与赋值是有所区别的,赋值是与原数据指向同一对象,而浅拷贝则指向了不同对象。
- 浅拷贝只对数据的引用地址进行复制,只复制保存在栈内存中的地址,指向堆内存中存储的值却还是只有一份,这样当对其中一个变量进行修改时,另一个就会受影响;
- 而深拷贝则是对源对象进行多层级的复制,使栈内存中地址和堆内存中值都复制一份,彻底切断跟源对象的联系,这样彼此的修改就不会受影响。
- 对比
| 和原数据是否指向同一对象 | 第一层数据的基本数据类型 | 原数据中的子对象 | |
|---|---|---|---|
| 赋值 | 是 | 修改会受影响 | 修改会受影响 |
| 浅拷贝 | 否 | 修改不会受影响 | 修改会受影响 |
| 深拷贝 | 否 | 修改不会受影响 | 修改不会受影响 |
# 浅拷贝的实现方法
先简单讲几个浅拷贝的方法。
# 1. Object.assign
ES6新增的方法:Object.assign (opens new window),用于将所有可枚举属性的值从一个或多个源对象复制到目标对象。它将返回目标对象。
const obj1 = {a: {b: 1}, c: 2};
const obj2 = Object.assign({}, obj1);
obj1.a.b = 2;
obj1.c = 4;
console.log(obj1.a, obj1.c); // {b: 2} 4
console.log(obj2.a, obj2.c); // {b: 2} 2
源对象obj1的a属性的值是一个对象,Object.assign()拷贝得到的是这个对象的引用。这个对象的任何变化,都会反映到目标对象上面。
# 2. for...in+hasOwnProperty
for...in这个方法在上面已经简单用过,这里对其进行完善。
// shallowCopy(目标对象,源对象1,源对象2,...)
function shallowCopy(target) { // target为传入的第一个参数:目标对象
// 第一个为目标对象,从第二个参数开始,循环传入的源对象
for (var i = 1; i < arguments.length; i ++) {
var source = arguments[i];
for(var prop in source) { // 循环每个源对象的属性
if (source.hasOwnProperty(prop)) {
target[prop] = source[prop];
}
}
}
return target;
}
const obj1 = {a: {b: 1}, c: 2, name: 'tom'};
const obj2 = shallowCopy({}, obj1, {c: 3});
obj1.a.b = 2;
obj1.name = 'rose';
console.log(obj1); // {a: {b: 2}, c: 2, name: "rose"}
console.log(obj2); // {a: {b: 2}, c: 3, name: "tom"}
这个方法也是只复制第一层,和Object.assign功能类似。
# 3. ...扩展运算符
const obj1 = {a: {b: 1}, name: 'tom'};
const obj2 = {...obj1};
obj1.a.b = 2;
obj1.name = 'rose';
console.log(obj1); // {a: {b: 2}, name: "rose"}
console.log(obj2); // {a: {b: 2}, name: "tom"}
只拷贝obj1的第一层,基础类型拷贝值,复杂类型拷贝引用。
# 4. slice和concat方法(仅限数组)
let a = [1,[2,3],4];
// let b = a.slice(); // 返回新数组
let b = a.concat(); // 返回新数组
a[0] = 11;
a[1][1] = 33;
console.log(a); // [11, [2, 33], 4]
console.log(b); // [1, [2, 33], 4]
# 深拷贝的实现方法
# 1. 基础版
JSON.parse+JSON.stringify
function cloneJSON(obj) {
return JSON.parse(JSON.stringify(obj))
}
const obj1 = {a: {b: 1, c: {d: 2, e: isNaN, f: /\s/g, g: new Date(), h: undefined, i: Symbol('symbol') }}};
const obj2 = cloneJSON(obj1);
console.log(obj2.a.c); // {d: 2, f: {…}, g: "2021-04-13T11:20:24.860Z"}
console.log(new Date()); // Tue Apr 13 2021 19:20:24 GMT+0800 (中国标准时间)
这个是最简单的方法,虽然能满足大多数场景,但兼容性不好,无法对正则进行精准拷贝,无法正确拷贝Date格式,无法对函数、undefined、Symbol这些类型的数据进行拷贝。
// 会把值为undefined的过滤掉
JSON.parse(JSON.stringify({a: 1, b: undefined, c: null}))
// {a: 1, c: null}
- 栈溢出
还有一个很重要的问题是,用这个方法,当源对象层级过深时,容易出现栈溢出。怎么看出来会栈溢出的呢?这里用一个方法判断一下:
// 定义一个自动生成嵌套对象的函数
// deep 生成对象层数,每层的数据个数
function createObjData(deep, breadth) {
var data = {};
var temp = data;
for(var i = 0; i < deep; i ++) { // 遍历层数
temp = temp['data'] = {}; // *** 这行代码实现了层级嵌套 ***
for (var j = 0; j < breadth; j ++) { // 遍历个数,赋值
temp[j] = j;
}
}
return data;
}
console.log(createObjData(3,3)); // {data: {0:0,1:1,2:2, data:{0:0,1:1,2:2, data:{0:0,1:1,2:2}}}}
createObjData这个方法挺巧妙的,主要是利用对象=赋值运算符可以复制对象引用的特性,实现数据层级的嵌套。下面试一下刚才的cloneJSON方法复制层级过多的数据会不会栈溢出:
cloneJSON(createObjData(10000)); // Maximum call stack size exceeded
果不其然,直接报错了:Maximum call stack size exceeded。
这个问题先放一放,我们先看看另外的实现深拷贝的方法:
# 2. 进阶版:递归实现
for...in+hasOwnProperty递归实现。
这个方法是刚才浅拷贝中
for...in+hasOwnProperty方法的延伸,浅拷贝中只是用于对源对象第一层数据的复制,这里可以通过递归对更深层级的数据进行复制。
// 先定义个判断object类型(引用类型)判断的方法
// 这个方法可以对Object,Array,Set,Map,Date,RegExp这些引用类型的数据进行判断,它们的实例都是对象;考虑Function和null这两种特殊类型
function isObject(obj) {
return typeof obj !== null && (obj === 'object' || obj === 'function');
}
function deepCopy(obj) {
if (!isObject(obj)) return obj; // 如果不是引用类型直接返回当前值
var res = Array.isArray(obj) ? [] : {}; // 数组兼容
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
var val = obj[key];
var type = Object.prototype.toString.call(val); // 判断类型
if (type === '[object Object]' || type === '[object Array]') {
res[key] = deepCopy(val); // 如果是对象或数组,递归调用
} else {
res[key] = val; // 其他类型,直接赋值
}
}
}
return res;
}
const obj1 = {a: {b: 1, c: {d: 2, e: isNaN, f: /\s/g, g: new Date(), h: undefined, i: Symbol('symbol') }}};
const obj2 = deepCopy(obj1);
console.log(new Date()); // Tue Apr 13 2021 19:22:14 GMT+0800 (中国标准时间)
console.log(obj2.a.c); // {d: 2, f: /\s/g, g: Tue Apr 13 2021 19:22:14 GMT+0800 (中国标准时间), h: undefined, e: ƒ, i: Symbol('symbol')}
该方法实现了:
- 实现了对
函数、正则、Symbol、undefined等类型数据的拷贝,也能正确复制Date格式; - 提供了是否是引用类型的判断方法,对参数类型做了校验;
- 兼容了数组类型
接着用刚才的createObjData方法看看还会不会发生栈溢出呢?
console.log(deepCopy(createObjData(10, 10000))); // 可以正常打印,说明数据长度不会影响发生栈溢出
console.log(deepCopy(createObjData(10000, 10))); // Uncaught RangeError: Maximum call stack size exceeded
果不其然,报错依旧:Maximum call stack size exceeded
- 循环引用
还有一种容易发生栈溢出的情况需要注意一下:
var a = {};
a.a = a; // 循环嵌套
deepCopy(a); // Maximum call stack size exceeded 这样直接死循环了
cloneJSON(a); // Uncaught TypeError: Converting circular structure to JSON
JSON.stringify内部做了循环引用的检测,所以没有发生死循环导致栈溢出,但还是报错了。
- 引用丢失
再来看另一种情况:
var b = {};
var a = {a1: b, a2: b};
console.log(a.a1 === a.a2) // true
var c = deepCopy(a);
console.log(c.a1 === c.a2) // false
一个对象a,a下面的两个键值都引用同一个对象b,经过深拷贝后,a的两个键值会丢失引用关系,从而变成两个不同的对象,这又出现了另一个问题:引用丢失。
整理下上面两种方法容易出现的问题:
- 递归调用容易出现栈溢出;
- 循环引用会死循环,报错;
- 会发生引用丢失。
下面针对这些问题简单分析一下:
# 问题分析
- 栈溢出
栈溢出的主要原因还是递归;在js中递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易发生“栈溢出”错误。解决这个问题的方法就是不用递归,改用循环来实现。
刚才的方法中循环是使用for...in实现,其实for...in循环需要读属性和原型链,当数据比较多时就会比较慢,可以采用while循环,提高循环效率。
- 循环引用
循环引用是因为对象的属性间接或直接的引用了自身,最终导致死循环;解决循环引用问题,我们可以额外开辟一个存储空间,来存储当前对象和拷贝对象的对应关系,当需要拷贝当前对象时,先去存储空间中找,有没有拷贝过这个对象,如果有的话直接返回,如果没有的话继续拷贝,这样就巧妙化解的循环引用的问题。
这个存储空间,需要可以存储key-value形式的数据,且key可以是一个引用类型,可以选择Map (opens new window)这种数据结构。
- 引用丢失
如果我们发现一个新对象就把这个对象和他的拷贝存下来,每次拷贝对象前,都先看一下这个对象是不是已经拷贝过了,如果拷贝过了,就不需要拷贝了,直接用原来的,这样我们就能够保留引用关系了;解决方法和循环引用的方法差不多。
除了上面的这些问题,还有一个重要的问题需要考虑:
- 对其他引用类型的兼容
js的有好几种引用数据类型,包含:
Set、Map、Function、RegExp等等,在上一个方法中只兼容了Object和Array类型,还需要对其他类型进行兼容处理
接下来先用while循环来实现深拷贝,解决递归爆栈的问题:
# 3. 轻奢版:while循环实现
function deepCopyLoop(target) {
if (!isObject(target)) return target; // 如果不是对象的话直接返回当前值
const root = Array.isArray(target) ? [] : {}; // 初始化root,兼容数组
const type = (targ) => {return Object.prototype.toString.call(targ)}; // 判断类型
// 初始化一个栈,
const stackList = [
{
parent: root, // 父节点
key: undefined,
data: target // 需要拷贝的节点
}
]
// 循环遍历stackList
while(stackList.length) {
let node = stackList.pop(); // 移除栈的最后一个元素:pop() 方法用于删除并返回数组的最后一个元素
let {parent, key, data} = node;
// 初始化赋值目标,key为undefined则拷贝到父元素,不是则拷贝到子元素
let res = parent;
if (typeof key !== 'undefined') {
res = parent[key] = type(data) === '[object Array]' ? [] : {};
}
// 获取keys信息
let keys = type(data) === '[object Array]' ? data : Object.keys(data);
let i = 0;
// while循环遍历
while(i < keys.length) {
let key = type(data) === '[object Array]' ? i : keys[i];
// console.log(i, key);
if (data.hasOwnProperty(key)) { // 判断是否含有这个属性
let val = data[key];
// 如果是对象或数组,就在stackList中添加一组数据,不是则直接赋值
if (type(val) === '[object Object]' || type(val) === '[object Array]') {
stackList.push({
parent: res, // 将res赋值给parent,之后再次循环stackList时,进行相同的判断
key, // 保存key
data: val //
})
} else {
res[key] = val;
}
}
i ++;
}
}
return root;
}
试一下看看还有没有栈溢出问题:
console.log(deepCopyLoop(createObjData(10000, 10))); // {data: {…}}
正常打印,果然解决了!
- 关于
while里面的代码的执行逻辑有点绕,需要静下心来好好梳理,其实并不复杂,大致就是定义一个list用于保存拷贝信息,对每项数据进行循环,如果里面存在数组或对象,就生成一组新的拷贝信息,push到这个list中,继续循环遍历; - 由于刚开始初始化栈list的时候已经将
root赋值给parent,之后又将parent赋值给res,之后的操作就是循环每组数据的data,将数据拷贝到res中,一层层嵌套下去,最终root中就获取到所有拷贝的数据。
接下来,主要要做的就是用
Map提供数据缓存,解决死循环和引用丢失的问题;并对其他类型做兼容。
# 4. 最终版
直接上完整代码吧~
/*
*常用数据类型
* 这里按是否可遍历分为两类,可遍历的如对象、数组,里面可以添加其他类型数据,需要单独处理
*/
// 可遍历的数据类型
const mapTag = '[object Map]';
const setTag = '[object Set]';
const arrayTag = '[object Array]';
const objectTag = '[object Object]';
const argsTag = '[object Arguments]';
// 不可遍历的数据类型
const boolTag = '[object Boolean]';
const dateTag = '[object Date]';
const numberTag = '[object Number]';
const stringTag = '[object String]';
const symbolTag = '[object Symbol]';
const errorTag = '[object Error]';
const regexpTag = '[object RegExp]';
const funcTag = '[object Function]';
// 可遍历的数据类型
const deepTag = [mapTag, setTag, arrayTag, objectTag, argsTag];
// 克隆不可遍历的数据类型
function cloneOtherType(target, type) {
const Ctor = target.constructor; // 获取构造函数
switch (type) {
case boolTag:
case numberTag:
case stringTag:
case errorTag:
case dateTag:
return new Ctor(target); // 通过new创建一个新实例
case regexpTag: // 正则
return cloneReg(target);
case symbolTag: // symbol
return cloneSymbol(target);
case funcTag: // 函数
return cloneFunction(target);
default:
return null;
}
}
// 克隆symbol
function cloneSymbol(target) {
return Object(Symbol.prototype.valueOf.call(target));
}
// 克隆正则 https://juejin.cn/post/6844903775384125448
function cloneReg(target) {
const reFlags = /\w*$/;
const result = new target.constructor(target.source, reFlags.exec(target));
result.lastIndex = target.lastIndex;
return result;
}
// 克隆函数
function cloneFunction(func) {
const bodyReg = /(?<={)(.|\n)+(?=})/m; // 正则匹配函数体
const paramReg = /(?<=\().+(?=\)\s+{)/; // 正则匹配函数参数
const funcString = func.toString();
// 通过prototype来区分下箭头函数和普通函数,箭头函数是没有prototype的
if (func.prototype) {
const param = paramReg.exec(funcString);
const body = bodyReg.exec(funcString);
if (body) {
if (param) {
const paramArr = param[0].split(',');
// 使用new Function ([arg1[, arg2[, ...argN]],] functionBody)构造函数重新构造一个新的函数
return new Function(...paramArr, body[0]);
} else {
return new Function(body[0]);
}
} else {
return null;
}
} else {
// 直接使用eval和函数字符串来重新生成一个箭头函数;eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
return func || eval(funcString);
}
}
// 判断是否是引用类型
function isObject(obj) {
let type = typeof obj;
return obj !== null && (type === 'object' || type === 'function');
}
// 获取数据类型:调用Object原型上的toString()方法获取准确的引用类型
function getType(target) {
return Object.prototype.toString.call(target);
}
/**
* 获取不同类型的初始化数据
* 在上一个方法中通过:var res = Array.isArray(obj) ? [] : {}; 来初始化数据
* 这里可以通过原对象的constructor构造函数获取初始化数据
* 例如:const target = {}就是const target = new Object()的语法糖
*/
function getInit(target) {
let Fn = target.constructor;
return new Fn();
}
// 封装遍历方法:使用while循环进行遍历
function forEach(array, callback) {
let i = 0;
while(i < array.length) {
callback(array[i], i);
i ++;
}
return array;
}
// 深拷贝:轻奢版
function deepCopyPro(target, map = new Map()) {
// 如果是基础数据类型,直接返回参数本身
if (!isObject(target)) return target;
// 初始化
let type = getType(target);
let cloneTarget;
if (deepTag.includes(type)) { // 是可遍历的数据
cloneTarget = getInit(target); // 获取初始化数据
} else { // 是不可遍历数据
return cloneOtherType(target, type); // 直接返回克隆值
}
// 防止循环引用和引用丢失
if (map.get(target)) { // 检查map中有无克隆过的对象
return map.get(target); // 有则直接返回
}
map.set(target, cloneTarget); // 无则将当前对象作为key,克隆对象作为value进行存储,继续克隆
/**
* 接下来开始遍历克隆,这里主要克隆Set、Map、Array、Object四种数据类型
*/
// 克隆set
if (type === setTag) {
target.forEach(v => {
cloneTarget.add(deepCopyPro(v, map)); // 递归调用deepCopyPro,传入遍历的子元素,和已经缓存的map
})
return cloneTarget;
}
// 克隆map
if (type === mapTag) {
target.forEach((value, key) => {
cloneTarget.set(key, deepCopyPro(value, map)); // 递归调用deepCopyPro,传入遍历的子元素,和已经缓存的map
})
return cloneTarget;
}
// 克隆数组和对象
const keys = type === arrayTag ? undefined : Object.keys(target); // 是数组则先返回null,不是则用Object.keys获取所有key
forEach(keys || target, (val, key) => {
if (keys) { // 是对象
key = val;
}
cloneTarget[key] = deepCopyPro(target[key], map);
})
return cloneTarget;
}
测试一下:
// 深拷贝终极版测试
const map = new Map();
map.set('key', 'value');
map.set('name', 'tom');
const set = new Set();
set.add('name');
set.add('tom');
const obj3 = {
a: {name: 'tom'},
d: 2, e: isNaN, f: /\s/g, g: new Date(), h: undefined, i: Symbol('symbol'),
bool: new Boolean(true),
num: new Number(2),
str: new String(2),
symbol: Symbol(1),
error: new Error(),
empty: null,
map,
set,
func1: () => {
console.log('test');
},
func2: function (a, b) {
return a + b;
}
};
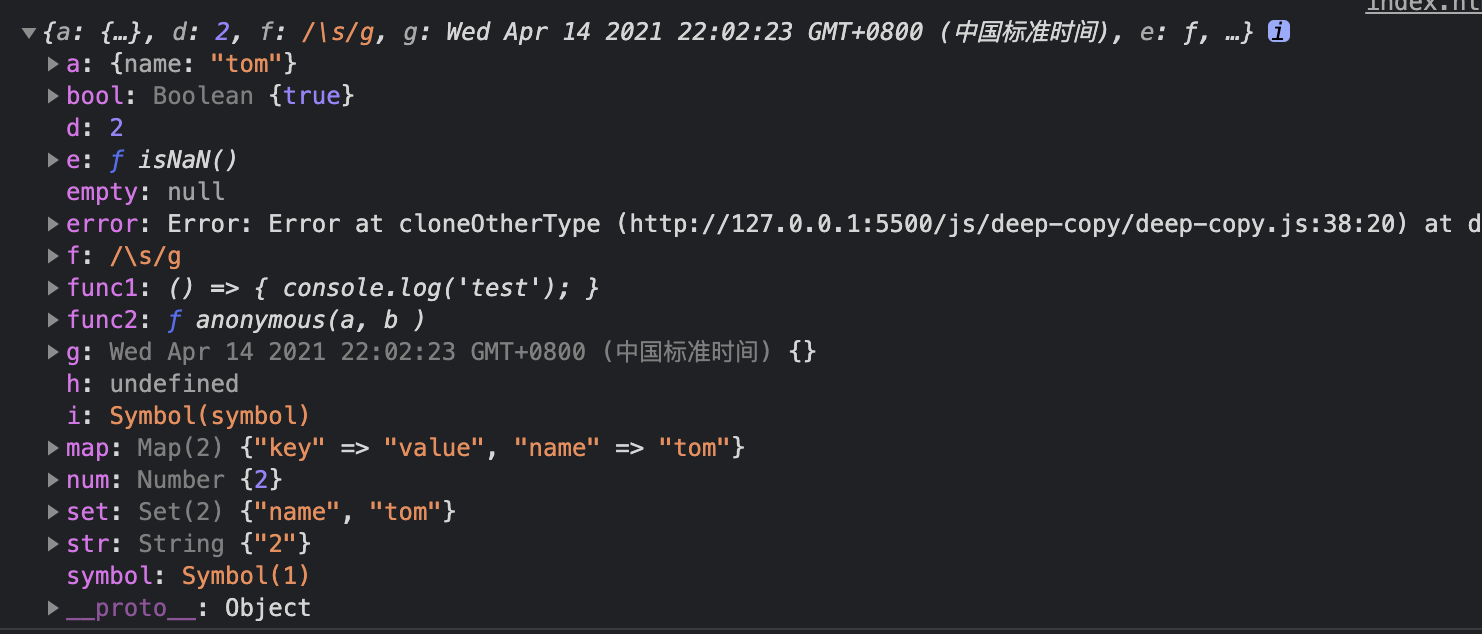
const obj4 = deepCopyPro(obj3);
console.log(obj4);
打印结果:
可以再用上面的方法试试循环引用和引用丢失的问题:
// 循环引用
var a = {};
a.a = a;
console.log(a);
console.log(deepCopyPro(a)); // {a:{...}}
// 引用丢失
var b = {};
var a = {a1: b, a2: b};
console.log(a.a1 === a.a2) // true
var c = deepCopyPro(a);
console.log(c); // {a1: {…}, a2: {…}}
console.log(c.a1 === c.a2) // true
发现都解决了!!!
其实上面的方法还是用递归实现,也是lodash主要实现方式,当然lodash的实现肯定更完善一些,兼容情况更多一些,但用递归其实还是有栈溢出的问题。这里在这个方法基础上继续改进,改用while循环实现,解决爆栈的问题:
// 深拷贝:终极版(while循环 + 缓存)
function deepCopyLoopLast(target, map = new Map()) {
if (!isObject(target)) return target;
let cloneTarget = getInit(target);// 初始化
// 初始化一个栈,
const stackList = [
{
parent: cloneTarget,
key: undefined,
data: target
}
]
while(stackList.length) { // 循环
let node = stackList.pop();
let {parent, key, data} = node;
let res = parent; // 初始化res
let type = getType(data);
if (typeof key !== 'undefined') {
res = parent[key] = getInit(data);
}
// 防止循环引用和引用丢失
if (deepTag.includes(type)) { // 是需要遍历的类型
if (map.get(data)) {
res = map.get(data);
continue; // 跳出此次循环
}
map.set(data, res);
}
// 克隆set
if (type === setTag) {
data.forEach((val, key) => {
let tt = getType(val);
if (deepTag.includes(tt)) {
stackList.push({parent: res,key,data: val})
} else {
res.add(val);
}
})
}
// 克隆map
if (type === mapTag) {
data.forEach((val, key) => {
let tt = getType(val);
if (deepTag.includes(tt)) {
stackList.push({parent: res,key,data: val})
} else {
res.set(key, val);
}
})
}
// 克隆数组和对象
const keys = type === arrayTag ? data : Object.keys(data);
let i = 0;
while(i < keys.length) { // 循环遍历
let key = type === arrayTag ? i : keys[i];
if (data.hasOwnProperty(key)) { // 判断是否含有这个属性
let val = data[key];
let tt = getType(val);
if (deepTag.includes(tt)) {
stackList.push({parent: res, key,data: val})
} else {
res[key] = val;
}
}
i ++;
}
}
return cloneTarget;
}
# 其他
- 递归为什么容易造成栈溢出?
首先了解下函数的堆栈概念:js中,每次函数调用会在内存形成一个“调用记录”, 保存着调用位置和内部变量等信息。如果函数中调用了其他函数,则js引擎将其运行过程暂停,去执行新调用的函数,新调用函数成功后继续返回当前函数的执行位置,继续往后执行。执行新调用的函数过程,也是将其推入到堆栈的最顶部并为其开辟一块内容。新函数执行完毕后将其推出堆栈,并回收内存。由此便形成了函数的堆栈。
在递归的使用中,函数会直接或间接调用自身;根据栈先进先出的特性,每递归一次,就占用内存生成调用记录并推入调用栈顶部,等到它执行完毕才将其推出,执行下面的调用栈;这样不停调用,不停累积,就会占用内存,直到占用内存超出浏览器负荷,就溢出了。
- 解决方法:尾递归。
当一个函数执行时的最后一个步骤是返回另一个函数的调用,这就叫做尾调用。这样就能保证在调用栈中始终只有一个调用记录,避免堆栈溢出。
用一个简单的阶乘函数对比下:
// 普通递归
function fac(n) {
if (n === 1) return 1;
return n * fac(n - 1); // 这不算尾调用,因为返回的不是fac,而是 n * fac
}
fac(5) // 120
// 尾递归
function fac1(n, total) {
if (n === 1) return total;
return fac1(n - 1, n * total); // 在最后一步返回函数调用
}
fac1(5, 1) // 120
# 备注
- 最后一个方法很多地方是参照
lodash里深拷贝的实现,有精力再继续研究下loadash深拷贝的源码 - 还有许多需要优化的点,比如对
Buffer的兼容,对函数的复制等等,有精力再研究 - 解决循环引用用的是
Map来进行缓存,也可以用WeakMap来进行缓存,因为WeakMap的键名所引用的对象都是弱引用,只要所引用的对象的其他引用都被清除,垃圾回收机制就会释放该对象所占用的内存,不用手动删除引用,会避免Map会对内存造成非常大的额外消耗的问题。 - 对于性能优化这块有时间还可以再继续深究下。
# 后记
# 递归优化版
/**
* 2022-04-04 添加
*
*/
// 判断类型的方法移到外部,避免递归过程中多次执行
const judgeType = origin => {
return Object.prototype.toString.call(origin).replaceAll(new RegExp(/\[|\]|object /g), "");
};
const reference = ["Set", "WeakSet", "Map", "WeakMap", "RegExp", "Date", "Error"];
function deepClone(obj) {
let res = null;
const type = judgeType(obj);
if (reference.includes(type)) { // 其他类型
res = new obj.constructor(obj);
} else if (['Array', 'Object'].includes(type)) { // 对象,数组
res = type === 'Array' ? [] : {};
for(let key in obj) {
// for...in会将原型中新增的属性和方法遍历出来, 所以需要判断一下是否是自身属性
if (obj.hasOwnProperty(key)) {
res[key] = deepClone(obj[key]); // 递归
}
}
} else {
res = obj;
}
return res;
}
const map = new Map();
map.set("key", "value");
map.set("ConardLi", "coder");
const set = new Set();
set.add("ConardLi");
set.add("coder");
const target = {
field1: 1,
field2: undefined,
field3: {
child: "child",
},
field4: [2, 4, 8],
empty: null,
map,
set,
bool: new Boolean(true),
num: new Number(2),
str: new String(2),
symbol: Object(Symbol(1)),
date: new Date(),
reg: /\d+/,
error: new Error(),
func1: () => {
let t = 0;
console.log("coder", t++);
},
func2: function (a, b) {
return a + b;
},
};
//测试代码
const test1 = deepClone(target);
target.field4.push(9);
console.log('test1: ', test1);