 15
15
# NodeJs
# NodeJs基础
Node.js 是一个开源的、跨平台的 JavaScript 运行时环境。
- NodeJs特点:
- 异步非阻塞模型: Node.js采用了异步非阻塞的事件驱动模型,这使得它能够在单个线程上处理大量并发请求。相比之下,许多传统的后端语言(如Java、Python)通常采用多线程或多进程模型来处理并发,这可能会导致更大的系统资源消耗和开发复杂性。
- 性能: Node.js的异步模型和事件循环使其在处理I/O密集型任务(如网络请求、文件操作)方面表现出色。然而,对于计算密集型任务,其他编译型语言(如Java、C#)可能会更有优势。
- 解释型语言
Node.js底层是用C++编写,它使用了V8的开源引擎来执行JavaScript代码。V8引擎是由Google开发的,它主要用于将JavaScript代码编译成本地机器代码,以提高执行速度。Node.js还使用了libuv库来处理事件循环、异步I/O等操作,这使得Node.js能够实现非阻塞式的、高性能的网络应用程序。
Node.js底层的实现包括两个主要组件:
- V8引擎: 这是一个高性能的JavaScript引擎,负责将JavaScript代码编译成机器码并执行。它是Node.js的核心组件,使得Node.js能够运行JavaScript代码。
- libuv库: 这是一个跨平台的库,用于处理事件循环、异步I/O、文件系统操作等。它提供了对底层操作系统API的封装,使得Node.js可以实现非阻塞式的异步操作,从而达到高性能和高并发的目标。
# 事件循环
Node.js 中的事件循环则是自己实现的,基于 Ryan Dahl 开发的 libuv ,完成了事件循环与异步 I/O。

- Event Loop:
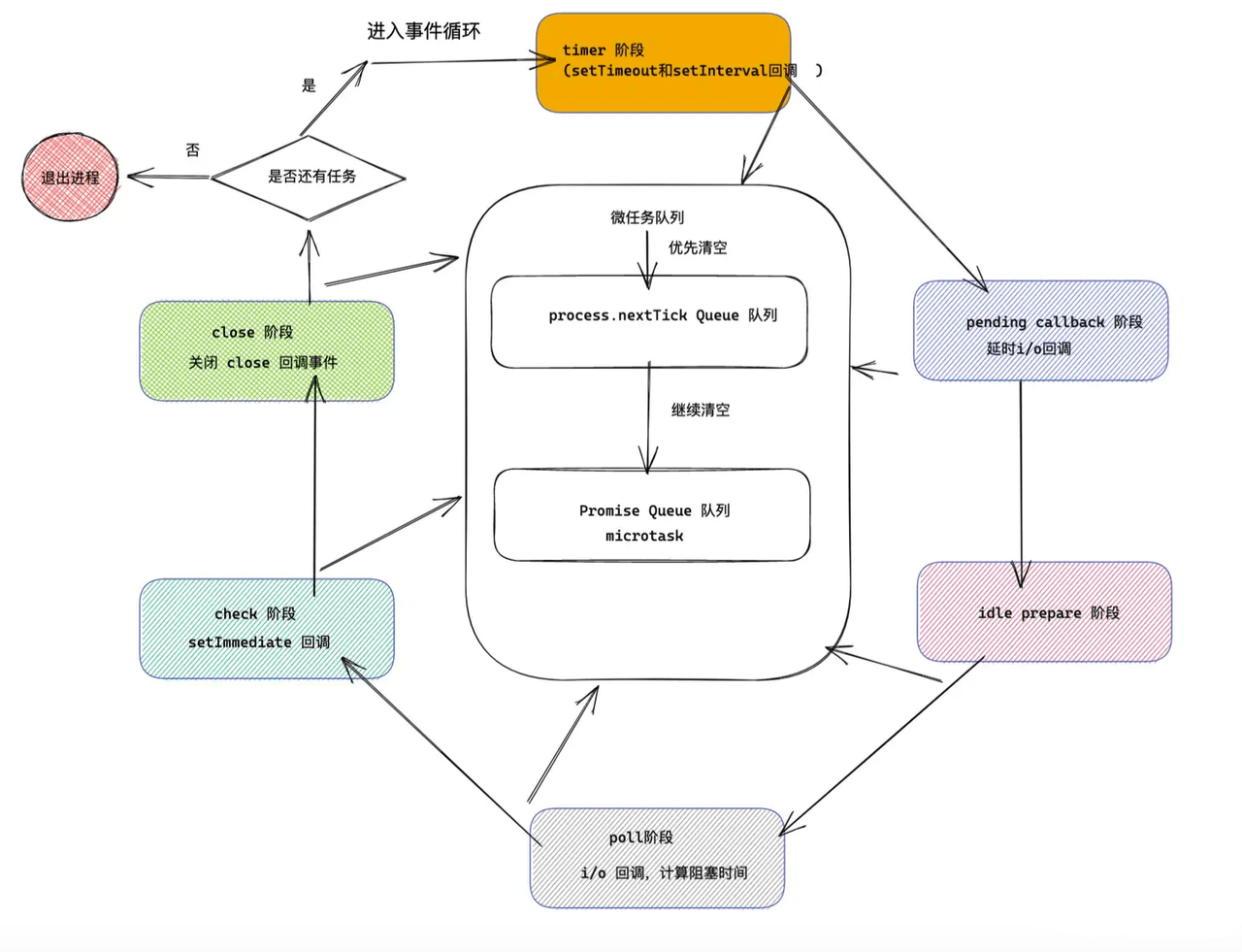
setImmediate()
- setImmediate 用于在当前事件循环迭代的末尾安排一个回调函数执行。它会在事件循环的 "check" 阶段执行。
- 当你想要在 I/O 操作完成后尽快执行回调时,setImmediate 是一个很好的选择。
process.nextTick()
- process.nextTick()是一个特殊的异步API,他不属于任何的Event Loop阶段。事实上Node在遇到这个API时,Event Loop根本就不会继续进行,会马上停下来执行process.nextTick()
queueMicrotask()
- queueMicrotask 用于将一个微任务(microtask)添加到微任务队列中,在当前事件循环迭代的末尾执行。微任务在 I/O 之后、事件循环阶段之前执行。
- 微任务通常用于需要尽快执行的、与 I/O 无关的操作,例如 promise 的回调函数。
- queueMicrotask 的优先级介于 process.nextTick 和 setImmediate 之间。
- 在一个异步流程里,setImmediate会比定时器先执行
// n.js
console.log('outer');
setTimeout(() => {
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
});
}, 0);
// node n.js
// outer > setImmediate > setTimeout
- setTimeout(fn, 1) https://nodejs.org/api/timers.html#timers_settimeout_callback_delay_args (opens new window)
setTimeout最小就是1ms,就算设置为0, 也是按1算~
// n.js
console.log('outer');
setTimeout(() => {
console.log('setTimeout');
}, 0); // setTimeout(fn, 1)
setImmediate(() => {
console.log('setImmediate');
});
// node n.js
// 执行时长 > 0.001s :outer > seTimeout > setImmediate
// 执行时长 < 0.001s :outer > setImmediate > seTimeout
//
console.log('outer');
setImmediate(() => {
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
});
});
//
- 一个例子:
// 特殊的异步API,会马上停下来执行process.nextTick()
process.nextTick(function(){
console.log('1');
});
process.nextTick(function(){
console.log('2');
// 放在 check 队列里面
setImmediate(function(){
console.log('3');
});
process.nextTick(function(){
console.log('4');
});
});
// 放在 check 队列里面
setImmediate(function(){
console.log('5');
process.nextTick(function(){
console.log('6');
});
setImmediate(function(){
console.log('7');
});
});
// 放在 timer 队列里面
// js执行已经超过0.001s,所以先执行 timer 队列里面的
setTimeout(e=>{
console.log(8);
new Promise((resolve,reject)=>{
console.log(8+'promise');
resolve();
}).then(e=>{
console.log(8+'promise+then');
})
},0)
// 放在 timer 队列里面
setTimeout(e=>{ console.log(9); },0)
// 放在 check 队列里面
setImmediate(function(){
console.log('10');
process.nextTick(function(){
console.log('11');
});
process.nextTick(function(){
console.log('12');
});
setImmediate(function(){
console.log('13');
});
});
console.log('14');
new Promise((resolve,reject)=>{
console.log(15);
resolve();
}).then(e=>{ // 放在微任务队列里面
console.log(16); // 微任务
})
/**
执行顺序:
14
15
1
2
4
16
8
8promise
8promise+then
9
5
6
10
11
12
3
7
13
*/
分析:
- 首先顺序执行: 将
process.nextTick是放在微任务队列中,不立即执行;异步任务放在check/timer队列中;执行同步任务:14, 15, 把微任务Promise放在微任务队列中; - 然后执行
process.nextTick:1,2,4,3放在check队列中,执行Promise微任务:16; - 然后执行timer队列:
8, 8+'promise', 之后继续执行唯一的微任务:8+'promise+then'; 之后继续执行timer队列:9; - 然后开始执行check队列:
5,6, 把7追加到check队列后面;之后继续执行第二个check任务:10,11,12, 把13追加到check队列后面;之后执行第三个check任务:3; 最后顺序执行追加的check任务:7,13
# Require
- 一个例子:
// a.js
const getMes = require('./b')
console.log('我是 a 文件')
exports.say = function(){
const message = getMes()
console.log(message)
}
// b.js
// const say = require('./a')
// const object = {
// name:'《React》',
// author:'Rico'
// }
// console.log('我是 b 文件')
// module.exports = function(){
// return object
// }
const say = require('./a')
const object = {
name:'《React》',
author:'Rico'
}
console.log('我是 b 文件')
console.log('打印 a 模块' , say) // 打印 a 模块 {}: a模块还没执行完,所以打印出来的是空对象
setTimeout(()=>{
console.log('异步打印 a 模块' , say) // 异步打印 a 模块 { say: [Function] }
},0)
module.exports = function(){
return object
}
// main.js
const a = require('./a')
const b = require('./b')
console.log('node 入口文件')
// node main.js
/**
我是 b 文件
打印 a 模块 {}
我是 a 文件
node 入口文件
异步打印 a 模块 { say: [Function (anonymous)] }
*/
main.js 和 a.js 模块都引用了 b.js 模块,但是 b.js 模块只执行了一次。
a.js 模块 和 b.js 模块互相引用,但是没有造成循环引用的情况。
module 和 Module:
module:在 Node 中每一个 js 文件都是一个 module ,module 上保存了 exports 等信息之外,还有一个 loaded 表示该模块是否被加载。
- 为 false 表示还没有加载;
- 为 true 表示已经加载
Module:以 nodejs 为例,整个系统运行之后,会用 Module 缓存每一个模块加载的信息。
- require原理伪代码:
// id 为路径标识符
function require(id) {
/* 查找 Module 上有没有已经加载的 js 对象*/
const cachedModule = Module._cache[id]
/* 如果已经加载了那么直接取走缓存的 exports 对象 */
if(cachedModule){
return cachedModule.exports
}
/* 创建当前模块的 module */
const module = { exports: {} ,loaded: false , ...}
/* 将 module 缓存到 Module 的缓存属性中,路径标识符作为 id */
Module._cache[id] = module
/* 加载文件 */
runInThisContext(wrapper('module.exports = "123"'))(module.exports, require, module, __filename, __dirname)
/* 加载完成 *//
module.loaded = true
/* 返回值 */
return module.exports
}
执行流程
- 首先执行
node main.js,那么开始执行第一行require(a.js); - 那么首先判断 a.js 有没有缓存,因为没有缓存,先加入缓存,然后执行文件 a.js (需要注意 是先加入缓存, 后执行模块内容);
- a.js 中执行第一行,引用 b.js。
- 那么判断 b.js 有没有缓存,因为没有缓存,所以加入缓存,然后执行 b.js 文件。
- b.js 执行第一行,再一次循环引用
require(a.js)此时的 a.js 已经加入缓存,直接读取值。接下来打印console.log('我是 b 文件'),导出方法。 - b.js 执行完毕,回到 a.js 文件,打印
console.log('我是 a 文件'),导出方法。 - 最后回到 main.js,打印
console.log('node 入口文件')完成这个流程。
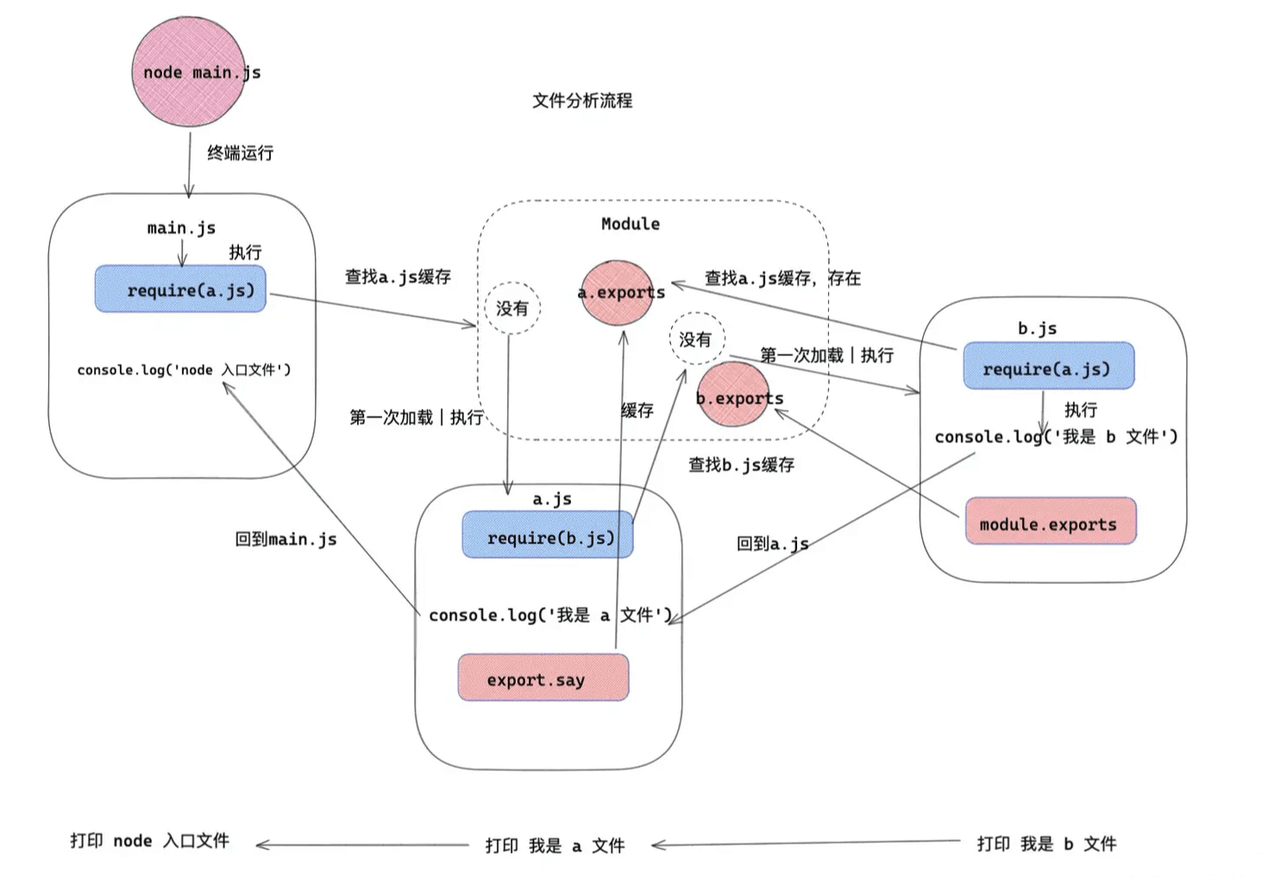
Node.js 中 CommonJS 模块的本质:
在 Node.js 中,CommonJS 的加载过程是由路径到源码,再到函数,最后通过执行函数注入灵魂,这某种意义上其实是返璞归真——IIFE
# CommonJS 与 ESM
通常一个 *.mjs 会被认为是 ECMAScript module,而一个 *.cjs 则会被认为是 CommonJS 模块。
如果是
*.js文件,则需要看离它最近的父 package.json 文件。这个就涉及到 Node.js 的包机制了,后续章节中会提。Node.js 在 v12.0.0 中,为 package.json 增加了 type 字段,用于判别其麾下的 *.js 文件是 ECMAScript module 还是 CommonJS 模块。若 type 值为module,则其*.js为ECMAScript module;若其值为 commonjs 或者不存在该值,则其 *.js 为 CommonJS 模块。
ECMAScript Modules 又称 ES Modules,缩写 ESM。它的设计非常“精简”与“官方”,从语法层面就完成了对模块的定义。像 CommonJS 也好,AMD、CMD 等也罢,都是通过三方实现函数和对象来模拟模块,而 ESM 则直接通过 import 与 export 语法来导入和导出模块。
CommonJS 是运行时做的模块加载和运行,它可以在代码执行一半的时候以动态的方式加载,这种方法在一些静态分析的时候会造成阻碍。
而 ESM 则是在模块顶部以语法的形式加载模块,完全可以做静态分析。
CommonJS 与 ECMAScript module 虽然是两套模块机制,但在 Node.js 中一定程度上是可以互通的:
CommonJS下无法使用 import 语法,ECMAScript module中没有require();ECMAScript module可以import CommonJS模块;- CommonJS 模块无法
require()ECMAScript module,但可以通过import()语法动态加载它。
# NPM生态
Node.js Package Manager => JavaScript Package Manager
{
"dependencies": {
"foo": "1.2.3 - 2.3.4", // 区间匹配: 表示匹配的版本需要在区间中间。如 1.2.3 - 2.3.4 代表 >= 1.2.3 <= 2.3.4
"bar": ">=1.0.2 <2.1.2", // <:小于某个版本, >=:大于等于某个版本
"baz": ">1.0.2 <=2.3.4", // >:大于某个版本, <=:小于等于某个版本
"boo": "2.0.1", // 精确匹配, =, 固定版本
"qux": "<1.0.0 || >=2.3.1 <2.4.5 || >=2.5.2 <3.0.0", // || 或
"asd": "http://asdf.com/asdf.tar.gz",
// 波浪匹配和上箭头匹配是最常见的 SemVer 匹配范围表示了
// 波浪匹配不允许动主次版本号,以修订版本号为最低匹配版本号去匹配。
"til": "~1.2", // ~1.2 则说明 >= 1.2.0 < 1.3.0-0,即等同于 1.2 或 1.2.x
"elf": "~1.2.3", // 如 ~1.2.3 则说明 >= 1.2.3 < 1.3.0-0
"dfd": "~0.2", // ~0.2 表示 >= 0.2.0 < 0.3.0-0。
"sds": "~0", // 只指定了主版本号,则将版本限定为对应主版本号下的所有版本号: ~0 表示 >= 0.0.0 < 1.0.0-0。
"two": "2.x", // 代表 2 为主版本的任意版本(>= 2.0.0 < 3.0.0-0)
"thr": "1.2.x", // 代表 1.2 为主次版本的任意版本(>= 1.2.0 < 1.3.0-0)
// 上箭头匹配表示第一个非零版本段后面的版本段可被升级
// 第一个非零版本段是主版本号,它后面的版本段是次版本号,也就说可匹配大于该版本号的所有该主版本号下的版本号
"dadsa": "^1.2.3", // >= 1.2.3 < 2.0.0-0;
"dsfs": "^0.0.3", // 只能匹配该修订号下所有先行版本号,即 >= 0.0.3 < 0.0.4-0。
"hgfd": "^1.2.3-beta.2", // >= 1.2.3-beta.2 < 2.0.0-0
"fsdfsd": "^0.0.3-beta.2", // >= 0.0.3-beta.2 < 0.0.4-0
"fsds": ""
"lat": "latest",
"dyl": "file:../dyl",
"xfd": "*" // 通配, * 代表任意版本(>= 0.0.0)
}
}
所有不带先行版本号的 SemVer 版本都比对应版本加上任意先行版本号的 SemVer 版本大,即
1.0.0是大于1.0.0-<xxx>的。
# npm / yarn / pnpm
npm
选择使用每个包管理器的方式会有所不同,但它们都有基本一致的概念。以上这些包管理器都可以执行以下指令:
- 读写数据
- 批量安装或更新所有依赖项
- 添加、更新和删除依赖项
- 运行脚本
- 发布包
npm2递归结构: 包冗余,包会很大
npm3 扁平结构:同名但不同版本的包是两个独立的包,而同层不能有两个同名子目录
npm5 lock锁: Yarn 首次引入的 => npm5借鉴
npm为了让开发者在安全的前提下使用最新的依赖包,在package.json中通常做了锁定大版本的操作,这样在每次npm install的时候都会拉取依赖包大版本下的最新的版本。这种机制最大的一个缺点就是当有依赖包有小版本更新时,可能会出现协同开发者的依赖包不一致的问题
package-lock.json文件精确描述了node_modules 目录下所有的包的树状依赖结构,每个包的版本号都是完全精确的
只要有这样一个 lock 文件,不管在哪一台机器上执行 npm install 都会得到完全相同的 node_modules 结果。
本地开发完成之后,CI平台会根据lock文件,拿到和本地完全一致的node modules
yarn
Q: 为什么更快?
- 并行安装:无论 npm 还是 Yarn 在执行包的安装时,都会执行一系列任务。npm 是按照队列执行每个 package,也就是说必须要等到当前 package 安装完成之后,才能继续后面的安装。而 Yarn 是同步执行所有任务,提高了性能
- 离线模式:如果之前已经安装过一个软件包,用Yarn再次安装时之间从缓存中获取,就不用像npm那样再从网络下载了
- yarn2 berry
在使用yarn 2.x安装以后,node_modules不会再出现,代替它的是.yarn目录,里面有cache和unplugged两个目录,以及外面一个.pnp.js
.yarn/cache里面放所有需要的依赖的压缩包,zip格式.yarn/unplugged是你需要手动去修改的依赖,使用yarn unplugin lodash可以把lodash解压到这个目录下,之后想修改什么的随意.pnp.js是PNP功能的核心,所有的依赖定位都需要通过它来
pnpm
pnpm 有一个 store 的概念,store 目录内部使用「基于内容寻址」的文件系统来存储磁盘上所有的文件。
基于内容寻址是一种文件系统的设计原则,以文件内容的哈希值作为文件的唯一标识符,并将文件存储在以哈希值命名的目录中。这样的设计使得相同内容的文件只会存储一次,避免了重复存储相同文件的问题。
在
pnpm的store目录中,每个文件的名称都是其内容的哈希值,因此同一个文件无论在多个项目中使用,都只会被存储一次。当安装或更新依赖项时,pnpm 会检查 store 目录中是否已经存在所需的文件,如果存在则直接复用,避免了重复的下载和存储。
# NodeJs原理详解
# 进程(process)
进程Process是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础,进程是线程的容器。进程是资源分配的最小单位。
Node.js 里通过
node app.js开启一个服务进程,多进程就是进程的复制(fork),fork 出来的每个进程都拥有自己的独立空间地址、数据栈,一个进程无法访问另外一个进程里定义的变量、数据结构,只有建立了 IPC 通信,进程之间才可数据共享。
chrome浏览器,一个应用,一个运行的js文件,都是一个进程~
# process模块
Node.js 中的进程 Process 是一个全局对象,无需 require 直接使用,给我们提供了当前进程中的相关信息。
process.env:环境变量,例如通过 process.env.NODE_ENV 获取不同环境项目配置信息process.nextTick:这个在谈及 Event Loop 时经常为会提到process.pid:获取当前进程idprocess.cwd():获取当前进程工作目录,process.platform:获取当前进程运行的操作系统平台- 进程事件:
process.on(‘uncaughtException’, cb)捕获异常信息、process.on(‘exit’, cb进程退出监听 process.title指定进程名称,有的时候需要给进程指定一个名称
# child_process子进程
- 使用
spawn()方法可以创建一个新的子进程,执行指定的命令。spwan返回的对象上载有流对象,分别是stdout和stderr,这两个对象可以监听数据流.
child_process.spawn(command[, args][, options])
exec()方法用于执行一个命令,并返回输出结果和错误。
child_process.exec(command[, options][, callback])
execFile()方法用于执行一个可执行文件,类似于spawn(),但不会创建一个新的shell
child_process.execFile(file[, args][, options][, callback])
fork()方法是用于创建一个新的 Node.js 子进程,该子进程执行指定的模块。
与 spawn() 不同,fork() 只需要指定要执行的模块,不需要指定命令和参数。
child_process.fork(modulePath[, args][, options])
// child_index.js
console.log('====进程id');
// child.js
const child_process = require('child_process');
// 1. spawn() 方法
// 使用 spawn() 方法可以创建一个新的子进程
const workerProcess = child_process.spawn('node',['child_index.js']);
// 监听 child_index.js 的输出
workerProcess.stdout.on('data',function(data){
console.log('spawn cmd data :'+data); // spawn cmd data :====进程id
})
// 监听 child_index.js 的错误输出
workerProcess.stderr.on('data',function(data){
console.log('spawn cmd error data :'+data);
})
// 监听 child_index.js 的关闭
workerProcess.on('close',function(code){
console.log('spawn cmd close :'+code); // spawn cmd close :0
})
// workerProcess.kill() // 杀死子进程
// kill -9 pid
// 2. exec() 方法
const cmd = 'ls -l'; // 要执行的shell命令
// 使用 exec() 方法可以创建一个新的子进程
child_process.exec(cmd,function(err,stdout,stderr){
if(err){
console.error('exec cmd error :'+stderr);
}else{
console.log('exec cmd data :'+stdout);
}
})
// 3. execFile() 方法
const child = child_process.execFile('node', ['child_index.js'], (error, stdout, stderr) => {
if(error){
console.error('execFile cmd error :'+stderr);
}else{
console.log('execFile cmd data :'+stdout);
}
});
// 4. fork() 方法
// 使用 fork() 方法可以创建一个新的子进程
const fork_child = child_process.fork('child_index.js');
// 监听子进程的消息事件
fork_child.on('message', (message) => {
console.log(`接收到子进程消息:${message}`);
});
// 向子进程发送消息
fork_child.send('Hello from parent process!');
# cluster多进程
web服务器:暴露3000端口 希望有多个进程处理3000端口
负载均衡load balancer
应用部署到多核服务器时,为了充分利用多核 CPU 资源一般启动多个 NodeJS 进程提供服务,这时就会使用到 NodeJS 内置的 Cluster 模块了。Cluster模块可以创建同时运行的子进程(Worker进程),同时共享同一个端口。每个子进程都有自己的事件循环、内存和V8实例。
NodeJS Cluster是基于Master-Worker模型的,Master负责监控Worker的状态并分配工作任务,Worker则负责执行具体的任务。Master和Worker之间通过IPC(进程间通信)传递消息,进程之间没有共享内存。
事实上,cluster 模块就是将
child_process和net模块的API组合起来实现的。cluster启动时,进程会在内部启动TCP服务器。而在调用cluster.fork()复制子进程时,会将这个TCP服务器端 Socket 的句柄发送给工作进程。
const cluster = require("node:cluster");
const http = require("node:http");
const numCPUs = require("node:os").cpus().length; // 当前系统有多少个cpu核
const process = require("node:process");
if (cluster.isMaster) { // 默认是主进程
//处理主进程逻辑
masterProcess();
} else {
//处理子进程逻辑
childProcess();
}
function masterProcess() {
console.log(`Master ${process.pid} is running`);
console.log(`Forking for ${numCPUs} CPUs`)
for (let i = 0; i < numCPUs; i++) { // 根据cpu核数创建子进程
cluster.fork();
}
}
function childProcess() {
http
.createServer((req, res) => { // 创建http服务
for (let i = 1e7; i > 0; i--) {} // 1e7 = 1 * 10^7 = 10000000
console.log(`Handling request from ${process.pid}`);
res.end(`Hello from ${process.pid}\n`);
})
.listen(8977, () => {
console.log(`Started ${process.pid}`);
});
}
/**
node cluster.js
Master 27948 is running
Forking for 8 CPUs
Started 27951
Started 27950
Started 27949
Started 27952
Started 27954
Started 27953
Started 27955
Started 27956
*/
// 模拟多并发的情况:
/**
➜ test-code curl http://127.0.0.1:8977
Hello from 27951
➜ test-code curl http://127.0.0.1:8977
Hello from 27950
➜ test-code curl http://127.0.0.1:8977
Hello from 27949
➜ test-code curl http://127.0.0.1:8977
Hello from 27952
➜ test-code curl http://127.0.0.1:8977
Hello from 27953
➜ test-code curl http://127.0.0.1:8977
Hello from 27954
*/
// 多个不同的进程在处理请求,这样就可以提高系统的吞吐量,提高系统的性能。
无论是 child_process 模块还是 cluster 模块,为了解决 Node.js 实例单线程运行,无法利用多核 CPU 的问题而出现的。核心就是父进程(即 master 进程)负责监听端口,接收到新的请求后将其分发给下面的 worker 进程。
# 进程间的通信
IPC, Inter Process Communication
- 主进程与子进程间的通信:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
process.title='Nodejs进程 from Zhou';
// 主进程代码
if (cluster.isMaster) {
console.log(`主进程 ${process.pid} 正在运行`);
// 创建子进程
console.log(`Forking for ${numCPUs} CPUs`);
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
// 监听子进程的退出事件
cluster.on('exit', (worker, code, signal) => {
console.log(`子进程 ${worker.process.pid} 已退出`);
});
// 在主进程中监听来自子进程的消息
cluster.on('message', (worker, message) => {
console.log(`主进程收到来自子进程 ${worker.process.pid} 的消息:${message}`);
});
// 向所有子进程发送消息
for (const id in cluster.workers) {
cluster.workers[id].send('Hello from master process!');
}
} else {
// 子进程代码
console.log(`子进程 ${process.pid} 正在运行`);
// 监听来自主进程的消息
process.on('message', (message) => {
console.log(`子进程 ${process.pid} 收到消息:${message}`);
});
// 向主进程发送消息
process.send('Hello from child process: ' + process.pid );
// 创建一个简单的 HTTP 服务器以演示子进程的工作
http.createServer((req, res) => {
res.writeHead(200);
res.end(`Hello, I am a child process! from ${process.pid}\n`);
}).listen(8793);
}
# 使用Cluster进行优雅的重启
当我们更新代码的时候,可能需要重新启动NodeJS。重新启动应用程序时,会出现一个小的空窗期:在我们重启单进程的NodeJS过程中,服务器会无法处理用户的请求
使用Cluster可以解决这个问题,具体做法如下:一次重新启动一个Worker,剩下的Worker可以继续运行处理用户的请求。
const cluster = require("node:cluster");
const http = require("node:http");
const numCPUs = require("node:os").cpus().length; // 当前系统有多少个cpu核
const process = require("node:process");
if (cluster.isMaster) { // 默认是主进程
//处理主进程逻辑
masterProcess();
} else {
//处理子进程逻辑
childProcess();
}
// 主进程管理子进程
function masterProcess() {
console.log(`Master ${process.pid} is running`);
let workers = [];
// fork 子进程
console.log(`Forking for ${numCPUs} CPUs`)
for (let i = 0; i < numCPUs; i++) {
const worker = cluster.fork();
workers.push(worker);
}
//
process.on("SIGUSR2", async () => {
restartWorker(0); // 重启子进程
function restartWorker(i) {
if (i >= workers.length) return;
const worker = workers[i];
console.log(`Stopping worker: ${worker.process.pid}`);
worker.disconnect();
//监听子进程的退出事件
worker.on("exit", () => {
//判断子进程是否完成disconnect过程并正常退出
if (!worker.exitedAfterDisconnect) return;
const newWorker = cluster.fork(); // fork新的子进程
newWorker.on("listening", () => {
//当新的子进程开始监听端口
//重启下一个子进程
restartWorker(i + 1);
});
});
}
});
}
function childProcess() {
http.createServer((req, res) => {
console.log("Worker :>> ", `Worker ${process.pid}`);
res.writeHead(200);
res.end("hello world\n");
})
.listen(8756);
console.log(`Worker ${process.pid} started`);
}
# 进程守护PM2
https://pm2.keymetrics.io/ (opens new window)
pm2 stop Name/processID停止某个服务,通过服务名称或者服务进程IDpm2 delete Name/processID删除某个服务,通过服务名称或者服务进程IDpm2 logs [Name]查看日志,如果添加服务名称,则指定查看某个服务的日志,不加则查看所有日志pm2 start app.js -i 4集群,-i 参数用来告诉PM2以cluster_mode的形式运行你的app(对应的叫fork_mode),后面的数字表示要启动的工作线程的数量。
如果给定的数字为
0,PM2则会根据你CPU核心的数量来生成对应的工作线程。注意一般在生产环境使用cluster_mode模式,测试或者本地环境一般使用fork模式,方便测试到错误。
pm2 reload Name pm2 restart Name应用程序代码有更新,可以用重载来加载新代码,也可以用重启来完成,reload可以做到0秒宕机加载新的代码,restart则是重新启动,生产环境中多用reload来完成代码更新!pm2 list查看pm2中所有项目pm2 monit用monit可以打开实时监视器去查看资源占用情况
# 线程(thread)
线程是操作系统能够进行运算调度的最小单位,首先我们要清楚线程是隶属于进程的,被包含于进程之中。一个线程只能隶属于一个进程,但是一个进程是可以拥有多个线程的。 -- 通用描述
单线程就是一个进程只开一个线程。 -- NodeJS
Q: Node.js 到底是单线程的还是多线程的?
基础回答:Node.js 是单线程的。
展开说说:Node.js 在用户代码层面是单线程的。
再严谨一些:Node.js 在
worker_threads模块出来之前,在用户层面是单线程的。
# worker_thread多线程
允许在一个 Node.js 实例中运行多个应用程序线程。相比创建多个进程更轻量,并且可以共享内存。进程间通过传输 ArrayBuffer 实例或共享 SharedArrayBuffer 实例来做到这一点。
worker_threads已被证明是充分利用CPU性能的最佳解决方案:
const { Worker, isMainThread, parentPort, workerData, MessageChannel } = require('worker_threads');
if (isMainThread) {
console.log('我是主线程', isMainThread); // 我是主线程 true
const worker = new Worker('./n.js');
} else {
console.log('我不是主线程', isMainThread); // 我不是主线程 false
}
- 例子:worker_threads 运算斐波那契数列:
// 子线程 worker.js
const {parentPort, workerData} = require("worker_threads");
// 接收主线程传递的参数 workerData
// 同时将计算结果通过 postMessage 发送给主线程
parentPort.postMessage(getFibonacciNumber(workerData.num))
// 通过子线程执行斐波那契的递归函数
function getFibonacciNumber(num) {
if (num === 0) {
return 0;
}
else if (num === 1) {
return 1;
}
else {
return getFibonacciNumber(num - 1) + getFibonacciNumber(num - 2);
}
}
// threads.js
// 主线程
const {Worker} = require("worker_threads");
let number = 30;
// 创建子线程, 执行worker.js, 并传入参数
const worker = new Worker("./worker.js", {workerData: {num: number}});
worker.once("message", result => {
console.log(`${number}th Fibonacci Result: ${result}`);
});
worker.on("error", error => {
console.log(error);
});
worker.on("exit", exitCode => {
console.log(`It exited with code ${exitCode}`);
})
console.log("Execution in main thread");
/**
node threads.js
Execution in main thread
30th Fibonacci Result: 832040
It exited with code 0
*/
# 多进程 vs 多线程
| 属性 | 多进程 | 多线程 | 比较 |
|---|---|---|---|
| 数据 | 数据共享复杂,需要用IPC;数据是分开的,同步简单 | 因为共享进程数据,数据共享简单,同步复杂 | 各有千秋 |
| CPU、内存 | 占用内存多,切换复杂,CPU利用率低 | 占用内存少,切换简单,CPU利用率高 | 多线程更好 |
| 销毁、切换 | 创建销毁、切换复杂,速度慢 | 创建销毁、切换简单,速度很快 | 多线程更好 |
| coding | 编码简单、调试方便 | 编码、调试复杂 | 编码、调试复杂 |
| 可靠性 | 进程独立运行,不会相互影响 | 线程同呼吸共命运 | 多进程更好 |
| 分布式 | 可用于多机多核分布式,易于扩展 | 只能用于多核分布式 | 多进程更好 |
# global模块
console.log()打印setTimeout和setInterval,延时器和定时器__dirname当前文件夹的绝对路径,path.join(__dirname, 'xxxx.js')
# DNS模块
dns.getServers: 返回当前正在使用的 ip地址,以字符串数组形式返回dns.lookup: 使用底层系统工具进行域名解析,返回主机名绑定ipdns.reverse: 执行反向域名系统查询,将 IPv4 或 IPv6 地址解析为主机名数组。
const dns = require('dns');
const servers = dns.getServers(); // 返回当前正在使用的 ip地址,以字符串数组形式返回
console.log('====dns.getServers', servers) // [ '10.33.176.66', '10.33.176.67' ]
// 使用底层系统工具进行域名解析,返回主机名绑定ip地址的数组
dns.lookup('www.baidu.com', {all: true}, (err, address) => {
if (err) {
console.log('====dns.lookup err', err)
}
console.log('====dns.lookup', address);
})
// 执行反向域名系统查询,将 IPv4 或 IPv6 地址解析为主机名数组。
dns.reverse('123.57.172.182', (err, hostname) => {
if (err) console.log('====dns.reverse err', err)
console.log('====dns.reverse', hostname)
})
# fs模块
Node.js 的文件系统模块是靠 libuv 提供的,而 libuv 在 Linux 之类的操作系统中,则是封装了系统提供的那些 API。层层套娃,在 Node.js 的 JavaScript 侧又多套了几层,最终到达了现在的样子。
//参数1: 文件的路径
//参数2(可选): 编码,如果设置了,返回一个字符串,如果没有设置,会返回一个buffer对象
//参数3: 回调函数
// readFile不会阻塞,readFileAsync 会阻塞
fs.readFile('data.txt', 'utf8', (err, data)=>{
if(err) return console.log('读取文件失败',err)
console.log('读取文件成功',data)
})
//参数1:文件的路径(如果文件不存在,会自动创建)
//参数2:写入的文件内容(注意:写入的内容会覆盖以前的内容)
//参数3:写文件后的回调函数
fs.writeFile('2.txt', 'hello world', err=>{
if(err) return console.log('写入文件失败', err)
console.log('写入文件成功')
})
//参数1:文件的路径(如果文件不存在,会自动创建)
//参数2:追加的文件内容(注意:写入的内容会覆盖以前的内容)
//参数3:追加文件后的回调函数
fs.appendFile('2.txt', '我是追加的内容', err=>{
if(err) return console.log('追加文件内容失败',err)
console.log('追加文件内容成功')
})
# Buffer 与Stream
- Buffer是数据以二进制形式临时存放在内存中的物理映射,stream为搬运数据的传送带和加工器,有方向、状态、缓冲大小。
- Buffer => utf8:如遇到非UTF-8数据会转换为 �。
- Buffer => utf16le:每个字符会使用2或4个字节进行编码。
- Buffer => latin1:指定了Unicode编码范围,超出会截断并映射为范围内的字符串。
- **流(stream)**是 Node.js 中处理流式数据的抽象接口。 stream 模块用于构建实现了流接口的对象。 Node.js 提供了多种流对象。 例如,HTTP 服务器的请求和
process.stdout都是流的实例。
# Path模块
使用 path.join() 方法,可以把多个路径片段拼接为完整的路径字符串,语法格式如下:
const path = require('path');
// 可以把多个路径片段拼接为完整的路径字符串
console.log( path.join(__dirname, '成绩.txt') )
// 使用 path.basename() 方法,获取到文件的名称(有无扩展名,与路径本身有无扩展名一致)
console.log( path.basename('index.html') ) // index.html
console.log( path.basename('a/b/c/index.html') ) // index.html
console.log(path.basename('/a.jpg')) // a.jpg
// path.extname() 方法,可以获取路径中的扩展名部分,语法格式如下:
console.log(path.extname('a/b/c/index.html') ) // .html
# http模块
http 模块是 Node.js 官方提供的、用来创建web 服务器的模块。
// 1.引入http模块
const http = require('http');
// 2.创建服务器
const server=http.createServer()
// 3.启动服务并监听
server.listen(3000,()=>{
console.log('你来辣');
})
// 4.监听用户的请求
server.on('request',(req,res)=>{
// 设置字符集为utf-8(让中文能被解析),写在第一行
res.setHeader('content-type','text/html;charset=utf-8')
console.log('莫西莫西');
// console.log(req.headers);
console.log(req.method); // 请求的方式
console.log(req.url); // 请求的地址
// res.statusCode=404 // 设置状态码
// res.statusMessage='not find' // 设置状态信息
// res.write('abc')
// res.end写在最后
res.end('<h1>牛</h1>')
})
# os模块
- networkInterfaces获取网络信息
- cpus:获取系统的CPU内核细腻,返回个数组
- totalmem:系统总共内存容量
- freemem:系统空余内存变量
- hostname:系统主机名
- version: 系统内核版本的字符串
- platform: 主机操作系统平摊
- type: 主机的操作系统平台名称,可能的值为'aix'、'darwin'、'freebsd'、'linux'、'openbsd'、'sunos'、以及 'win32'。
- uptime: 操作系统正常运行时间
# Express.js
Express (opens new window)是一个基于Node平台的web应用开发框架
Express框架的核心是 中间件
ExpressJS helloworld (opens new window)
# 中间件
cors
express-session
express-jwt & jsonwebtoken
Swagger
# 数据库
在Web应用发展的初期,那时关系型数据库受到了较为广泛的关注和应用,原因是因为那时候Web站点基本上访问和并发不高、交互也较少。而在后来,随着访问量的提升,使用关系型数据库的Web站点多多少少都开始在性能上出现了一些瓶颈。
而随着互联网技术的进一步发展,各种类型的应用层出不穷,这导致在当今云计算、大数据盛行的时代,对性能有了更多的需求,主要体现在以下四个方面:
- 低延迟的读写速度:应用快速地反应能极大地提升用户的满意度
- 支撑海量的数据和流量:对于搜索这样大型应用而言,需要利用PB级别的数据和能应对百万级的流量
- 大规模集群的管理:系统管理员希望分布式应用能更简单的部署和管理
- 庞大运营成本的考量:IT部门希望在硬件成本、软件成本和人力成本能够有大幅度地降低
# SQL
SQL数据库是一个使用结构化查询语言(SQL)来存储、检索和操作数据的关系数据库。它有资格作为一种编程语言。SQL数据库是最常见的关系数据库类型,它们被各种各样的企业和组织所使用。
- MySQL =>
SELECT * FROM xxTable JOIN TyTable on xxTable.xx = TyTable.yy WHERE xx = xxx ORDER by xxx - PostgreSQL =>
- TypeORM
# NoSQL
同时具备了高性能、可扩展性强、高可用等优点~
- Redis
Redis是现在最受欢迎的NoSQL数据库之一,Redis是一个使用ANSI C编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库。
- MongoDB => JSON
MongoDB 是非关系型的数据库(NoSQL),属于文档型数据库,文档数据库就是为了解决关系数据库带来的问题。最大的特点是
no-schema,可以存储和读取任意的数据。
存储的数据格式就是 JSON(或者 BSON)。JSON 格式我们都比较熟悉,比如 Rest API 请求返回的 Response 就是 JSON 格式的。JSON 格式的数据和 XML 个格式的区别是 JSON 更简单,没有那么多的标签来定义字段名。也就是说 JSON 是自描述的。另外 JSON 格式存进 MongoDB 中后,即使读取一个 JSON 中不存在的字段也不会导致 SQL 那样的语法错误。
- Mongoose => ODM
Mongoose 是一个用于Node.js的对象模型工具,用于在Node.js应用程序中与MongoDB数据库进行交互。它是一个MongoDB的ODM(对象文档映射器),允许你在应用程序中定义数据模型、验证数据、执行查询以及与MongoDB数据库进行交互,而无需直接使用MongoDB的原始驱动程序。
- 如何写一个ExpressJS中间件?
展示了如何编写一个简单的 Express.js 中间件,它记录每个请求的时间戳:
// 导入 Express.js
const express = require('express');
const app = express();
// 自定义中间件函数
const logTimestamp = (req, res, next) => {
const timestamp = new Date().toLocaleString();
console.log(`[${timestamp}] - Request received for: ${req.url}`);
next(); // 调用 next() 以继续请求处理链
};
// 将中间件函数绑定到应用程序
app.use(logTimestamp);
// 路由处理
app.get('/', (req, res) => {
res.send('Hello, Express!');
});
// 启动 Express.js 应用程序
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
# 基于ExpressJS实现登录鉴权
登录态方案:JWT与Session
登录状态的保存问题的解决有两种方案:
- 服务端存储的 session + cookie 的方案
session + cookie 的给 http 添加状态的方案是服务端保存 session 数据,然后把 id 放入 cookie 返回,cookie 是自动携带的,每个请求可以通过 cookie 里的 id 查找到对应的 session,从而实现请求的标识。这种方案能实现需求,但是有 CSRF、分布式 session、跨域等问题,不过都是有解决方案的。
- 客户端存储的 jwt token 的方案
token 的方案常用 json 格式来保存,叫做 json web token,简称 JWT。
JWT 是保存在 request header 里的一段字符串(比如用 header 名可以叫 authorization),它分为三部分:header、payload、verify signature
- header 部分保存当前的加密算法
- payload 部分是具体存储的数据
- verify signature 部分是把 header 和 payload 还有 salt 做一次加密之后生成的。(salt,盐,就是一段任意的字符串,增加随机性)
这三部分会分别做 Base64,然后连在一起就是 JWT 的 header,放到某个 header 比如 authorization 中:
authorization: Bearer xxxxx.xxxxx.xxxx
请求的时候把这个 header 带上,服务端就可以解析出对应的 header、payload、verify signature 这三部分,然后根据 header 里的算法也对 header、payload 加上 salt 做一次解密,如果得出的结果和 verify signature 一样,就接受这个 token。
把状态数据都保存在 payload 部分,这样就实现了有状态的 http~
JWT 的方案是把状态数据保存在 header 里,每次请求需要手动携带,没有 session + cookie 方案的 CSRF、分布式、跨域的问题,但是也有安全性、性能、没法控制等问题。
const express = require('express');
//express-session
const jwt = require('jsonwebtoken');
const app = express();
app.use(express.json());
const secretKey = 'your-secret-key'; // 用于签名和验证JWT令牌的密钥
const users = []; // 用于模拟用户数据
// 用户注册
app.post('/register', (req, res) => {
const { username, password } = req.body;
users.push({ username, password }); // 实际应用中应该存储到数据库并进行密码哈希
res.status(201).send('User registered successfully');
});
// 用户登录
app.post('/login', (req, res) => {
const { username, password } = req.body;
const user = users.find((u) => u.username === username);
if (!user || user.password !== password) {
res.status(401).send('Invalid credentials');
} else {
const token = generateToken(username);
res.status(200).json({ token });
}
});
// Authorazion: Bear Token
// 生成JWT令牌
function generateToken(username) {
const payload = { username };
return jwt.sign(payload, secretKey, { expiresIn: '1h' });
}
// 保护路由
app.get('/protected-route', verifyToken, (req, res) => {
console.log(req.user);
res.send(`Welcome, ${req.user.username}!`);
});
// JWT令牌验证中间件
function verifyToken(req, res, next) {
const token = req.header('Authorization');
if (!token) return res.status(401).send('Access denied');
try {
const decoded = jwt.verify(token, secretKey);
req.user = decoded;
next();
} catch (error) {
res.status(400).send('Invalid token');
}
}
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
# Koa
https://koajs.com/ (opens new window)
Koa 是 Express 的轻量级版本。它是一个中间件框架,没有像 Express 那样的额外模块(比如,没有内置路由和模板引擎)。Koa 由与 Express 相同的团队开发。事实上,许多人认为 Koa 是“Express 5.0”,因为它的开发很大程度上是最初 Express 的所有权问题导致。
洋葱模型
# Koa与Express的区别
- 中间件链接方式
Express 中间件链是基于回调的,而 Koa 的则是基于 Promise 的。这就是为什么我们在 Express 中最后定义 errorMiddleware,在 Koa 中首先定义 handleError。
// express
const express = require('express');
const app = express();
//1
app.use(middleware1);
//2
app.use(middleware2);
//3
app.use(middleware3);
// koa
const Koa = require('koa');
const app = new Koa();
// 中间件1
app.use(async (ctx, next) => {
// 1
console.log('Middleware 1 - Before');
await next();
// 5
console.log('Middleware 1 - After');
});
// 中间件2
app.use(async (ctx, next) => {
// 2
console.log('Middleware 2 - Before');
await next();
// 4
console.log('Middleware 2 - After');
});
// 路由处理程序
app.use(async (ctx) => {
//3
console.log('Route Handler');
ctx.body = 'Hello, World!';
});
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
- 增强 Node vs 替换 Node
- Express 是 NodeJS 的一个 Web 框架。它通过为 Node 的 req 和 res 对象添加有用的方法和属性来增强其功能。
例如,Express 会向 http req 对象添加像 req.method 和 req.headers() 这样的内容,并向 http res 对象添加 res.sendFile()。
- Koa 是 NodeJS 的一个中间件框架。Koa 使用自己的上下文(ctx)替换或提取 Node 的 req 和 res 对象属性。
例如,
context.body = result可以为请求设置响应体。
- 更加轻量 Koa 比 Express 更轻量级。Koa 不像 Express 那样包含路由器或视图引擎模块。这些模块是单独存在的,可以很容易地被包含进来。在我们的示例中,你会注意到我们必须为 Koa 实例单独包含 koa-router,而Express 中已经内置这个功能。
# Next.js
React 服务端渲染应用框架
SSR: 利于爬虫,seo优化
https://nextjs.org/docs (opens new window)
# NestJs
Nest (NestJS) 是一个用于构建高效、可扩展的 Node.js 服务器端应用的框架。 它使用渐进式 JavaScript,构建并完全支持 TypeScript(但仍然允许开发者使用纯 JavaScript 进行编码)并结合了 OOP(面向对象编程)、FP(函数式编程)和 FRP(函数式反应式编程)的元素。
企业级服务端架构
用 Node 写一个 http 服务有三个层次:
- 直接使用 http、https 的模块 http.createServer((req, res) => { if(req.method === 'GET') })
- 使用 express、koa 这种库
- 使用 Nest 这种企业级框架 / EggJS
https://nest.nodejs.cn/ (opens new window)
# 架构
MVC 是 Model View Controller 的简写。MVC 架构下,请求会先发送给 Controller,由它调度 Model 层的 Service 来完成业务逻辑,然后返回对应的 View。
后端框架基本都是 MVC 的架构。
Nest 提供了 AOP (Aspect Oriented Programming)的能力,也就是面向切面编程的能力。
# 装饰器语法
装饰器在 TypeScript 等语言中被广泛使用,但是 JavaScript 装饰器的支持仍处于第 2 阶段提案中。但是,我们可以借助 Babel 和 TypeScript 编译器使用 JavaScript 装饰器。
类装饰器, 概念类似HOC
TS装饰器:
- 类装饰器
- 函数装饰器
- 属性装饰器
- 参数装饰器
# Nest与Express的关系
Express 只是一个处理请求的库,并没有提供组织代码的架构能力,代码可能写成各种样子。
所以企业级开发,我们会用对它封装了一层的库,比如 Nest。
Nest 提供了 IOC、AOP 等架构特性,规定了代码组织的形式,而且对 websocket、graphql、orm 等各种方案都提供了开箱即用的支持。
# Docker
隔离的环境 ,通过docker 配置文件,配置容器内部的运行环境, 通过暴露端口与容器外通信
# 数据库
MySQL
NoSQL
# Redis
做后端服务的时候,我们不会只用 mysql,一般会结合内存数据库来做缓存,最常用的是 redis。
# 例:实现扫码登录系统
- 二维码状态
- 未扫描
- 已扫描,等待用户确认
- 已扫描,用户同意授权
- 已扫描,用户取消授权
- 已过期
实现思路
- 首先PC端会有一个二维码展示页面:
- 服务端有个
qrcode/generate接口,会生成一个随机的二维码 id,生成二维码确认页面url, 同时将该url生成一个二维码; - 还有个
qrcode/check接口,会返回该二维码id的二维码状态,浏览器里可以轮询这个接口拿到二维码状态;
- 然后手机 APP 扫码,如果没登录,会先跳转到登录页面,登录之后会进入登录确认页面:
- 进入确认页后首先从url中拿到了二维码id,然后调用
qrcode/scan接口切换二维码状态为【已扫描,等待用户确认】,PC展示页通过轮询也会及时更新状态; - 之后 如果点击取消则调取消接口:
qrcode/cancel,点击确认则确认接口:qrcode/confirm, 可修改二维码为不同的状态;在调确认接口时,客户端会传用户token, 服务端拿到token校验用户是否信息,返回是否校验通过信息; - PC端轮询拿到状态后就可以进行后续处理了~
# 备注
如何在Linux中操作进程
查找与进程相关的PID号
ps aux | grep xx- Ps:
process status - Aux
- A: all 所有进程
- U:user
- X:显示后台进程和守护进程
- | :管道符号
- grep: 查找 字符串/正则
- Ps:
终止进程
kill -9 pid